
성능 개선의 첫걸음 = Reader 개선
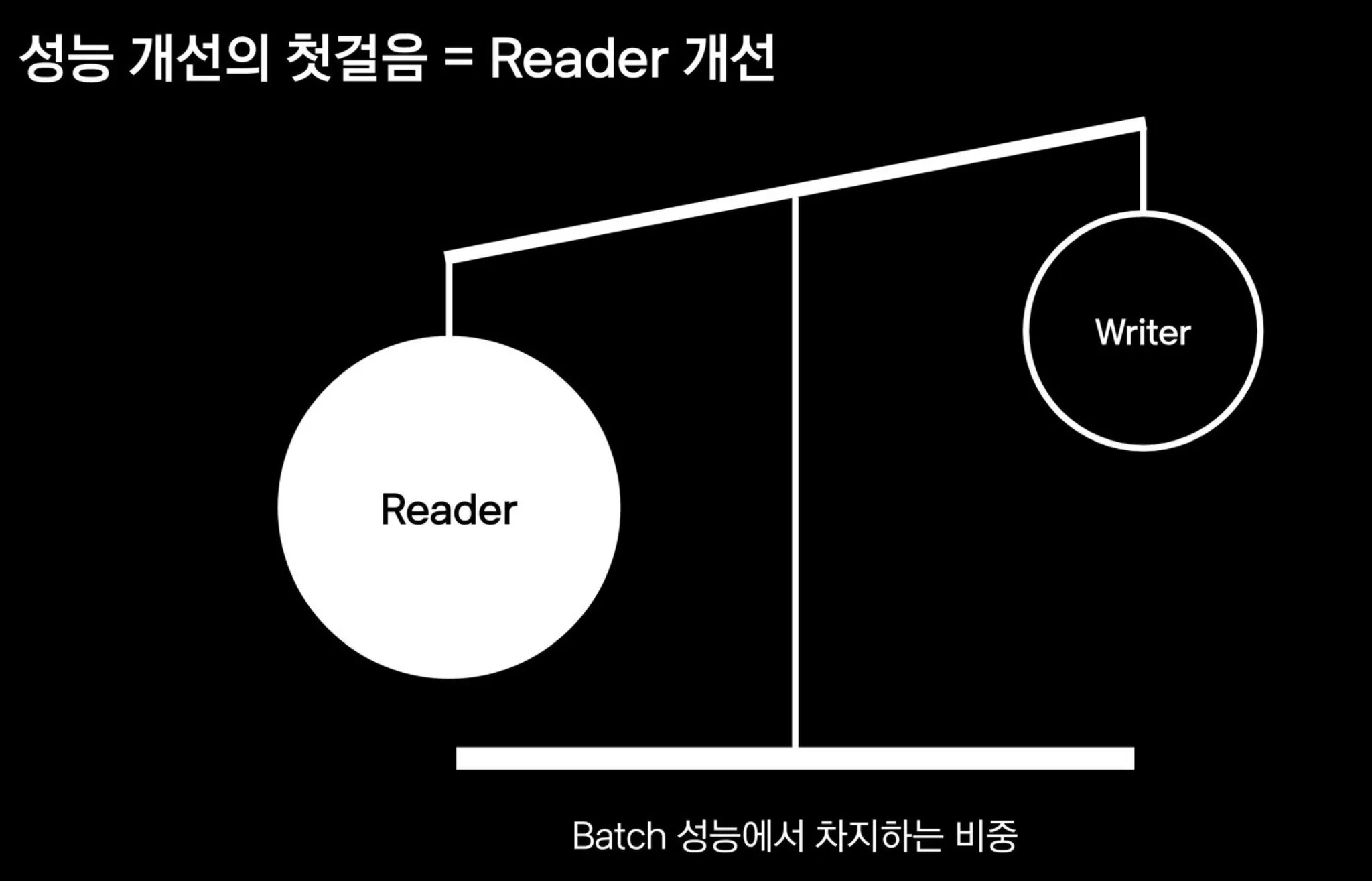
대량 데이터 READ
Batch 에서 데이터를 읽는 절대적인 방법
•
Chunk Processing
◦
이러한 처리는 대량 처리에 맞지 않다.
Select * from orders where category = "Book"
limit 3600, 100
SQL
복사
◦
ItemReader 문제점
▪
조회 결과 : 1억 건
select count(1) orders where category = 'Book' -- category가 index
SQL
복사
▪
조회 결과 : 100건, 조회 속도: 매우 빠름
select * from orders where category = "BOOK" limit 0, 100
SQL
복사
▪
조회 결과 : 100건, 조회 속도 : 매우느림
selet * from orders where category = "BOOK" limit 5000000, 100
SQL
복사
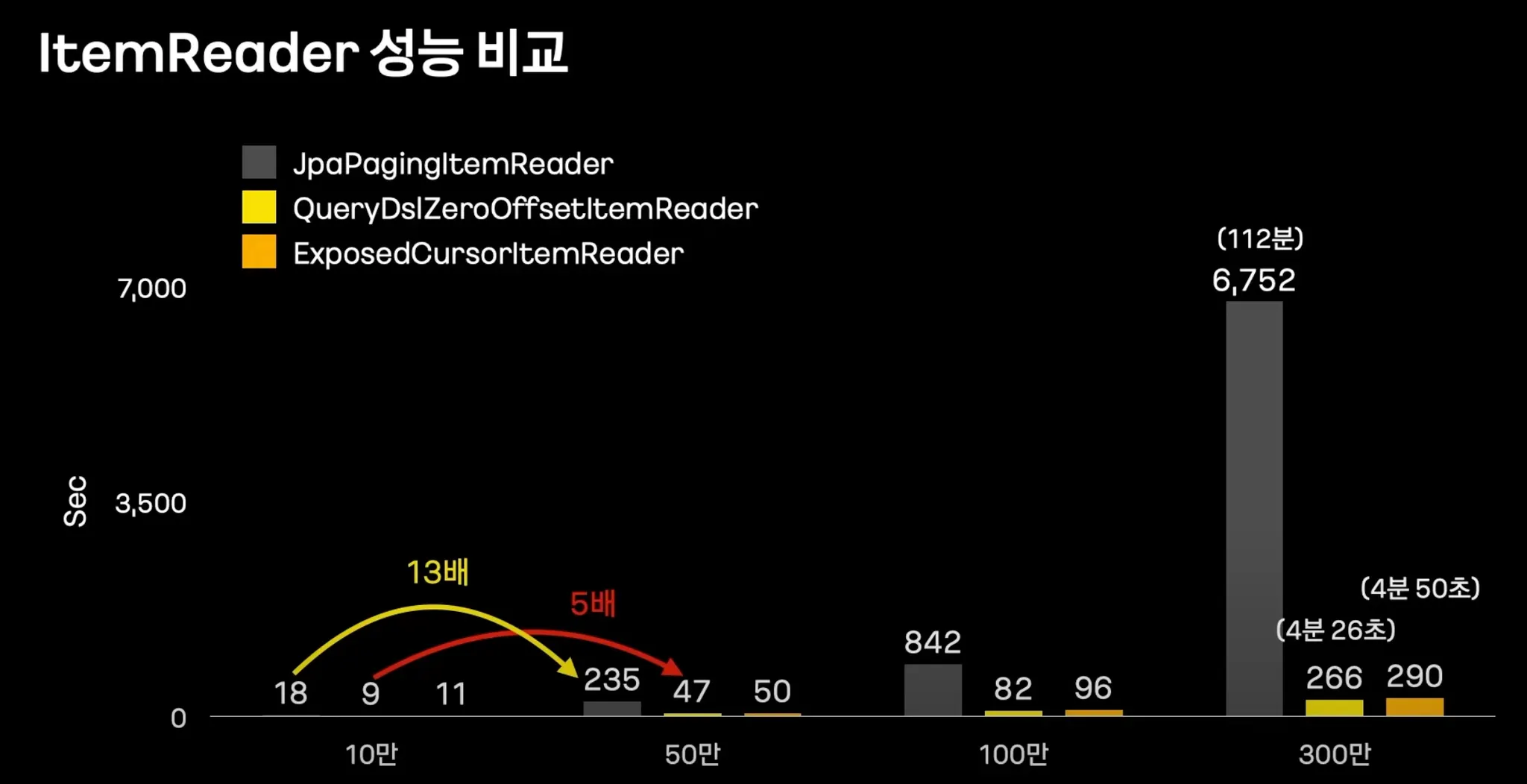
문제 : Offset이 커질수록 느려짐.
1. 해결방법 : ZeroOffsetItemReader

select * from orders where category = 'BOOK' and id > 0 limit 0, 100; -- zeroOffset
select * from orders where category = 'BOOK' and id > 5235 limit 0, 100; -- zeroOffset
select * from orders where cateogry = 'BOOK' and id > 967678332 limit 0, 100; -- zeroOffset
SQL
복사
•
offset이 항상 0이므로 조회 속도가 빠르다.
QueryDsl + ZeroOffsetItemReader
QueryDslZeroOffsetItemReader(
name = "orderQueryDslZeroOffsetItemReader",
pageSize = 1000,
entityManagerFactory = entityManagerFactory,
idAndSort = Asc,
idField = qOrder.id
) {
it.from(qOrder)
.innerJoin(qOrder.customer).fetchJoin()
.select(qOrder)
.where(qOrder.category.eq(CATEGORY.BOOK))
}
Java
복사
2. 해결방법 : Cursor
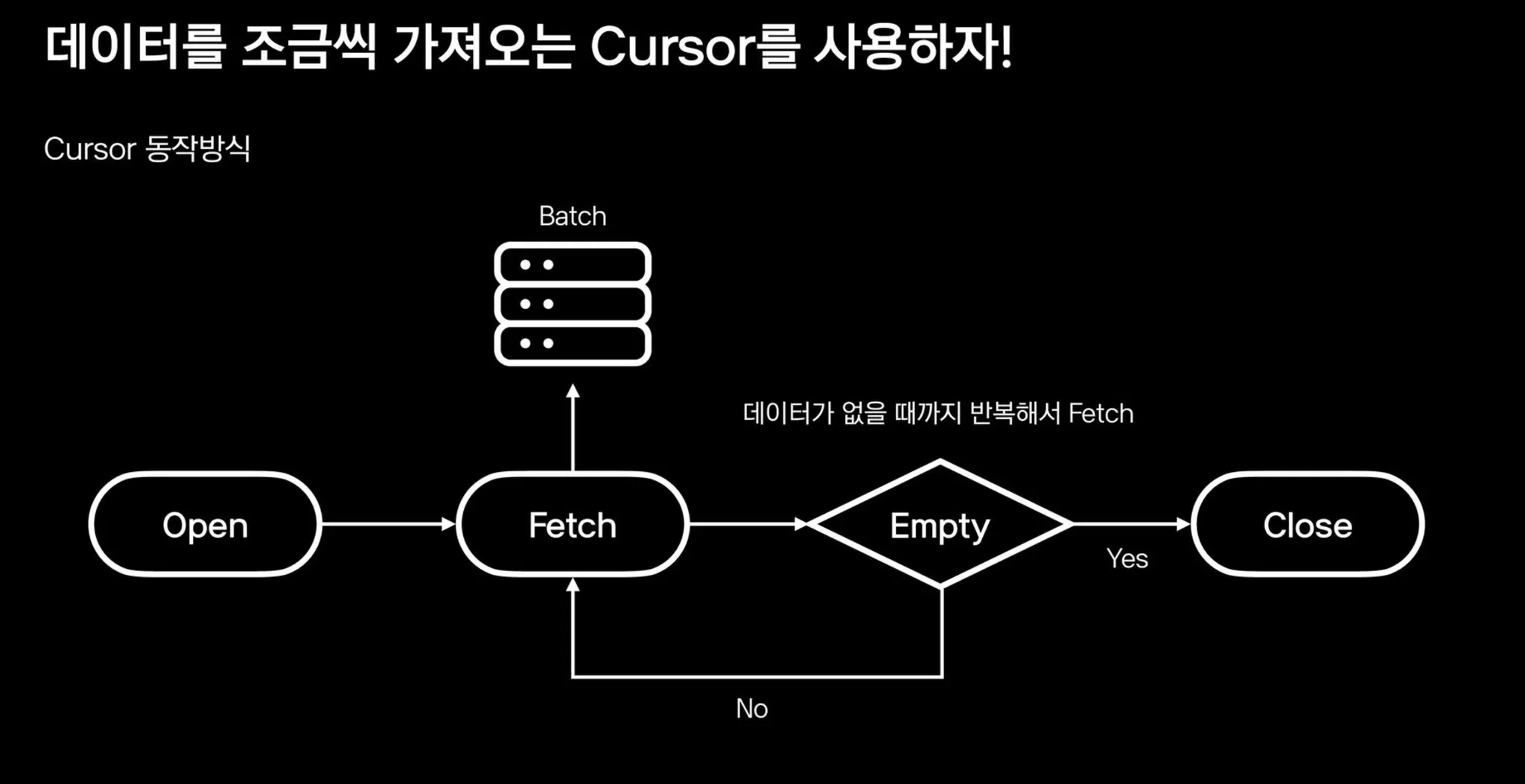
•
mysql Cusor : 데이터가 없을 때까지 일정갯수 데이터를 반복해서 제공해주는 방식
Spring 에서 지원해주는 Cursor
1.
JpaCursorItemReader
2.
JdbcCursorItemReader
3.
HibernateCursorItemReader
JpaCursorItemReader
•
MYSQL Cursor방식 데이터를 모두 읽고 서버에서 아이디레이터로 커서하는 방식이기 때문에 데이터 개수가 많으면 oom을 유발하는 치명적인 문제가있음. 사용하지 않기를 바람
JdbcCursorItemReader
HibernateCursorItemReader
•
HQL이나 네이티브 쿼리를 사용해야 되는 단점이 있음 → 쿼리 문자열 방식으로 구현하는것에 부담이 있음
→JetBrains Kotlin 기반의 Exposed가 있는데, 현재 우리 프로젝트는 Java기반이라 배치가 느리다면, ZeroOffsetItemReader로 해야 될 것으로 보임.
대량 데이터 READ 결론
데이터 Aggregation
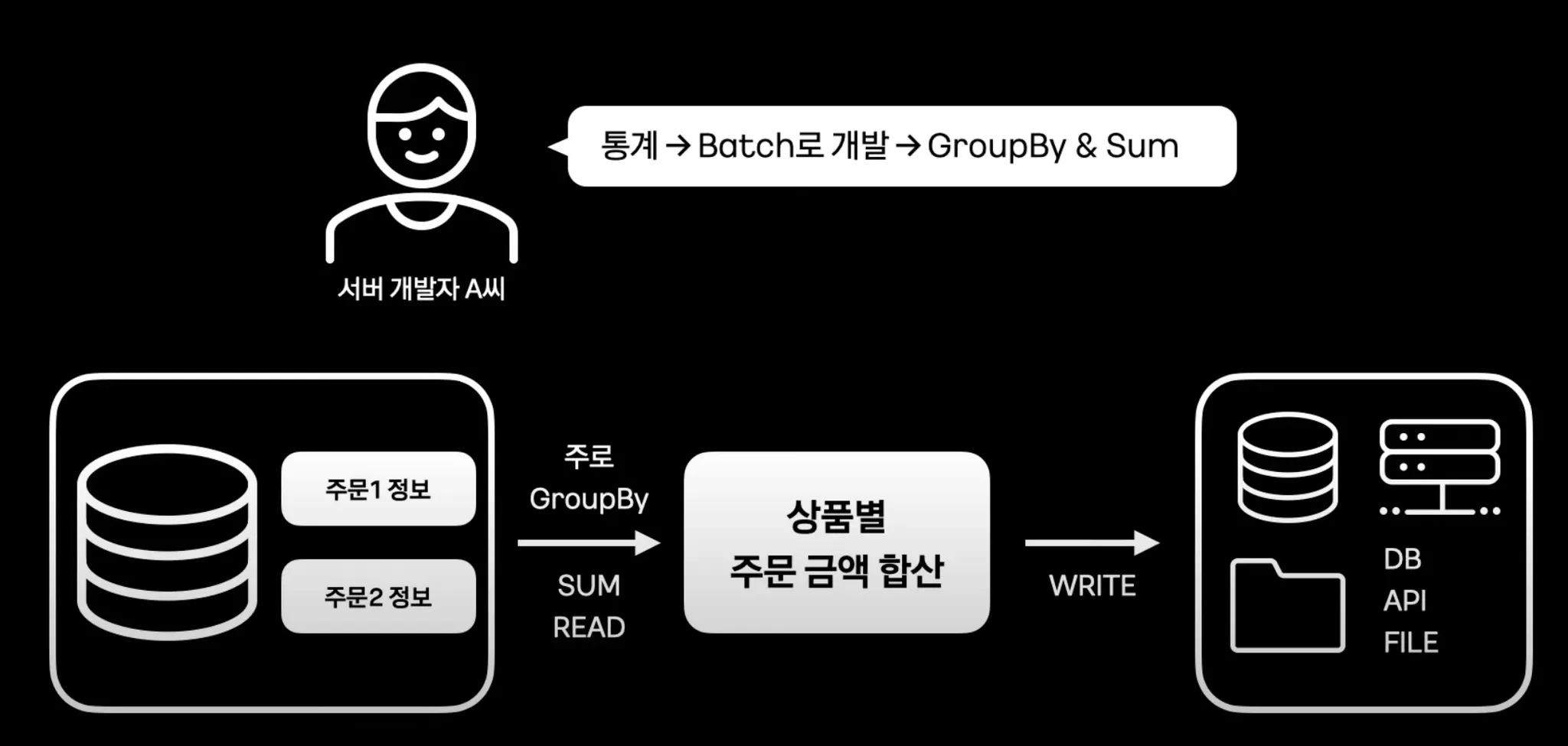
•
데이터가 적다면 매우 합리적으로 GroupBy 와 Sum을 사용해서 주문 금액 합산한다.
•
데이터가 많아지고 쿼리가 복잡해지면 문제가 발생한다.
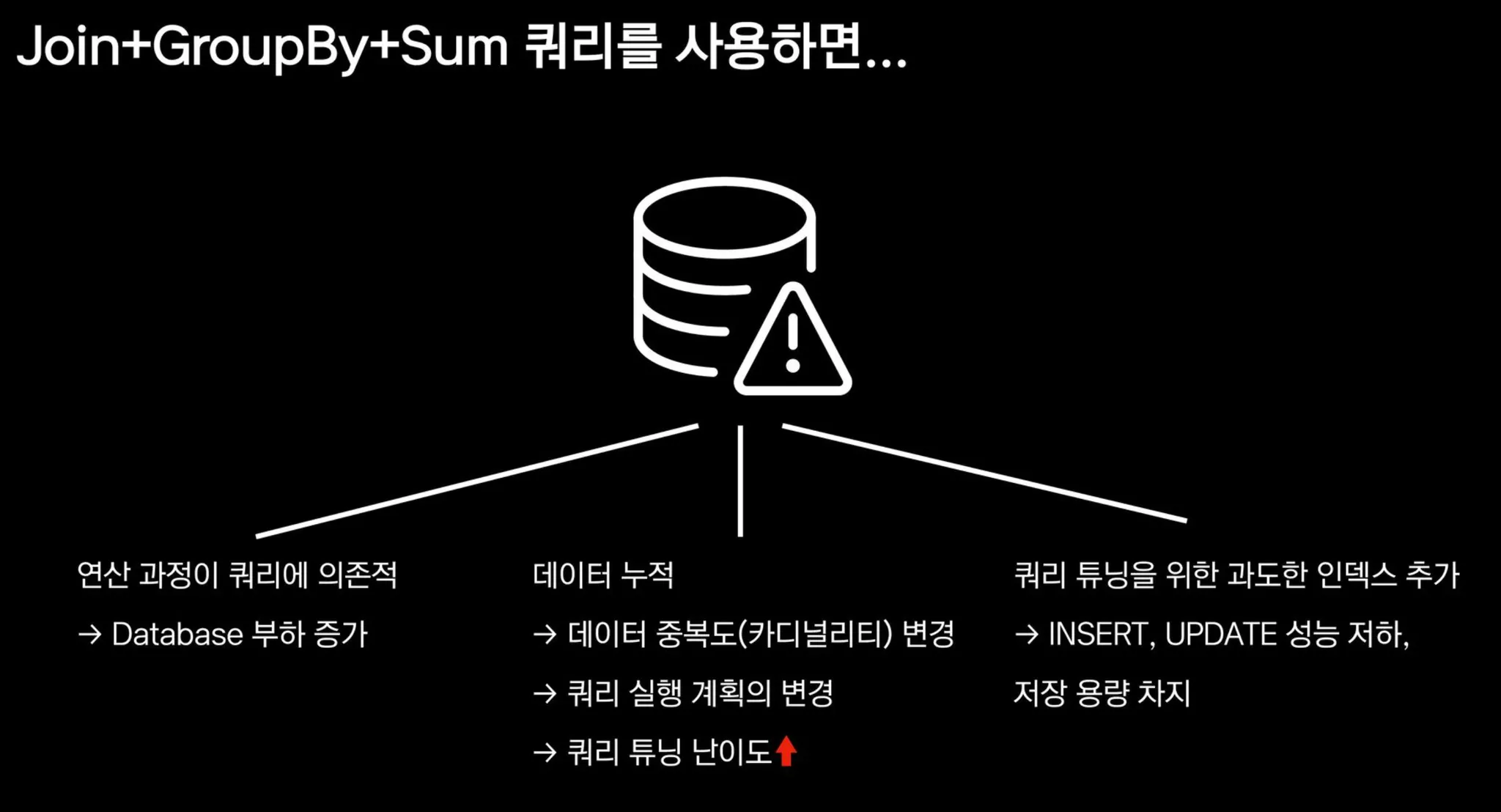
Join + Grouby + Sum 쿼리를 사용시
select
sum(o.amount),
count(1),
p.price,
p.proudct_id,
u.age
from orders o
inner join price p
on o.price_id = p.id
inner join user u
on o.user_id = u.id
where o.order_date = '2022-10-12'
group by p.product_id, u.age
order by p.product_id asc, u.age asc
limit 0, 100;
SQL
복사
•
연산 과정이 쿼리에 의존적 → Database 부하 증가
•
데이터 누적
◦
데이터 중복도 (카디널리티) 변경
◦
쿼리 실행 계획의 변경
◦
쿼리 튜닝 난이도 증가
•
쿼리 튜닝을 위한 과도한 인덱스 증가
◦
INSERT, UPDATE 성능 저하, 저장 용량 차지
ZeroOffset, Cursor를 사용하더라도 쿼리 자체가 느려진다.
GroupBy를 포기하자
select
p.price,
p.product_id,
u.age
from orders o
inner join price p
on o.price_id = p.id
inner join user u
on o.user_id = u.id
where o.order_date = '2022-10-12'
limit 0, 100;
SQL
복사
•
직접 Aggregation을 하자
직접 Aggregation하자
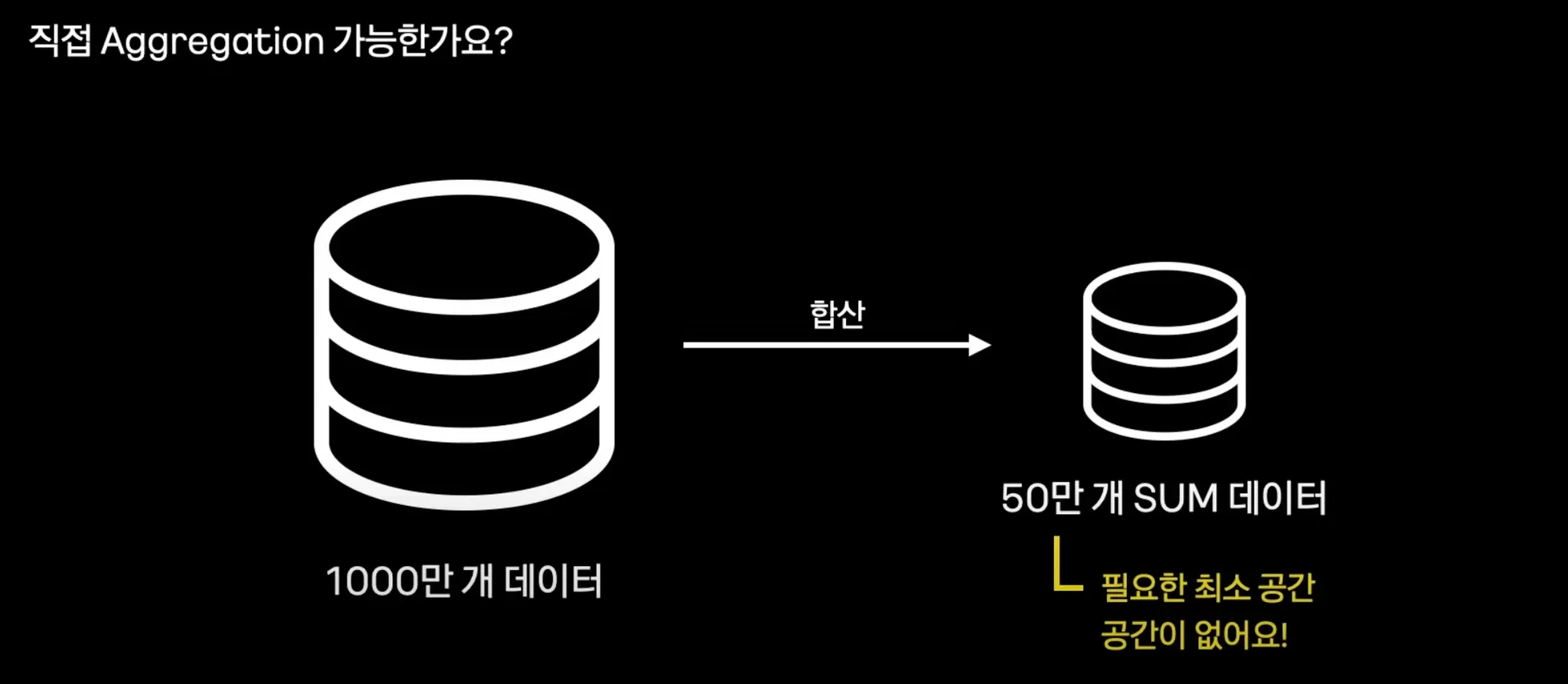
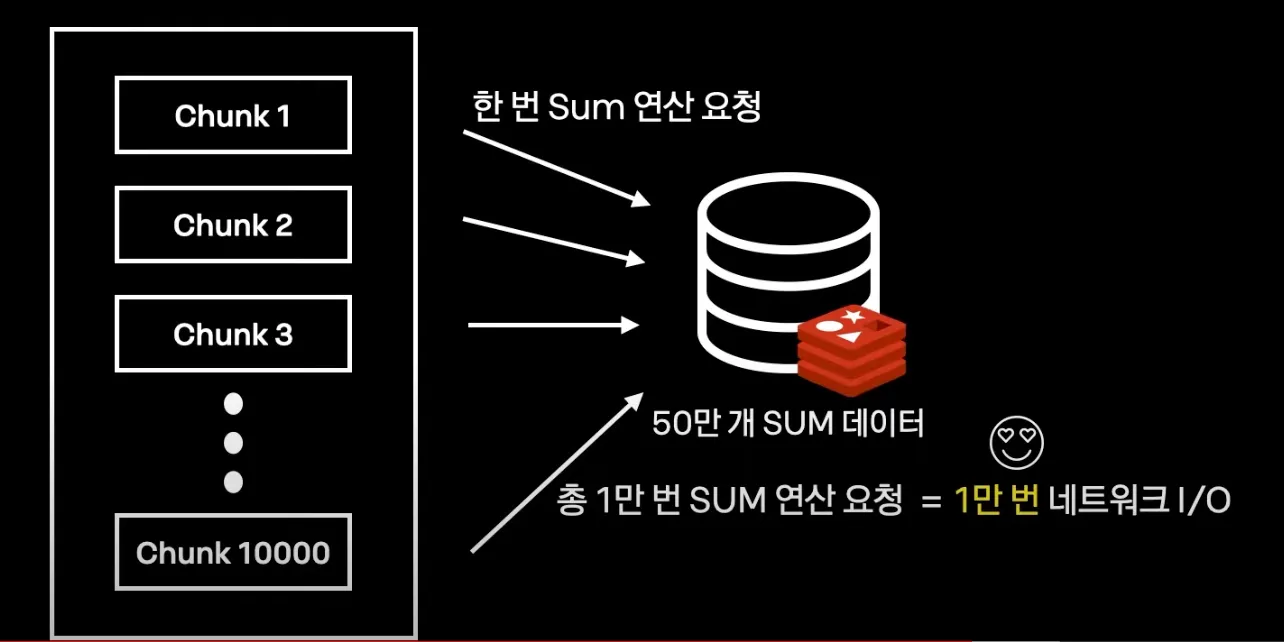
1000만 개의 데이터를 합산하여 50만 개 SUM을 어플리케이션에서 하게되면 공간이 없고, OOM을 유발할 수 있다.
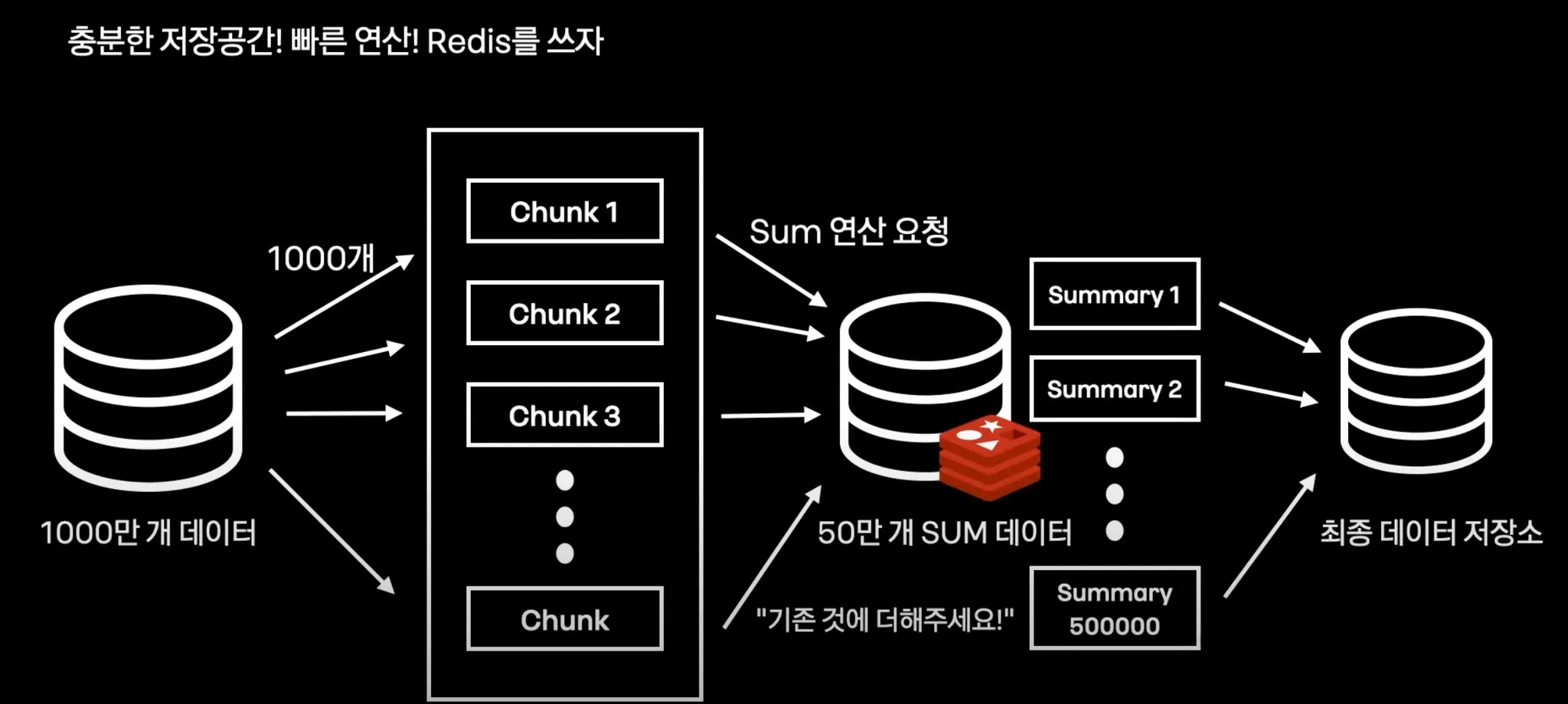
새로운 Arechitecture, Redis를 활용한 Sum
1.
1000만개의 데이터를 1000개로 나눠서 1만개 Chunk프로세스를 만든다.
2.
Sum 연산을 Redis에 요청을 한다.
3.
이렇게 반복해서 1만개의 chunk 프로세스를 합산한다.
4.
redis에 50만개의 sum 데이터가 만들어진다.
5.
결과물을 최종 데이터 저장소에 저장한다.
Aggregation Tool로 Redis를 도입 한 이유
1.
연산 명령어 hincrby, hincrbyfloat 지원
2.
50만 개는 쉽게 저장하는 넉넉한 메모리
3.
In-Memory DB 빠른 저장가능
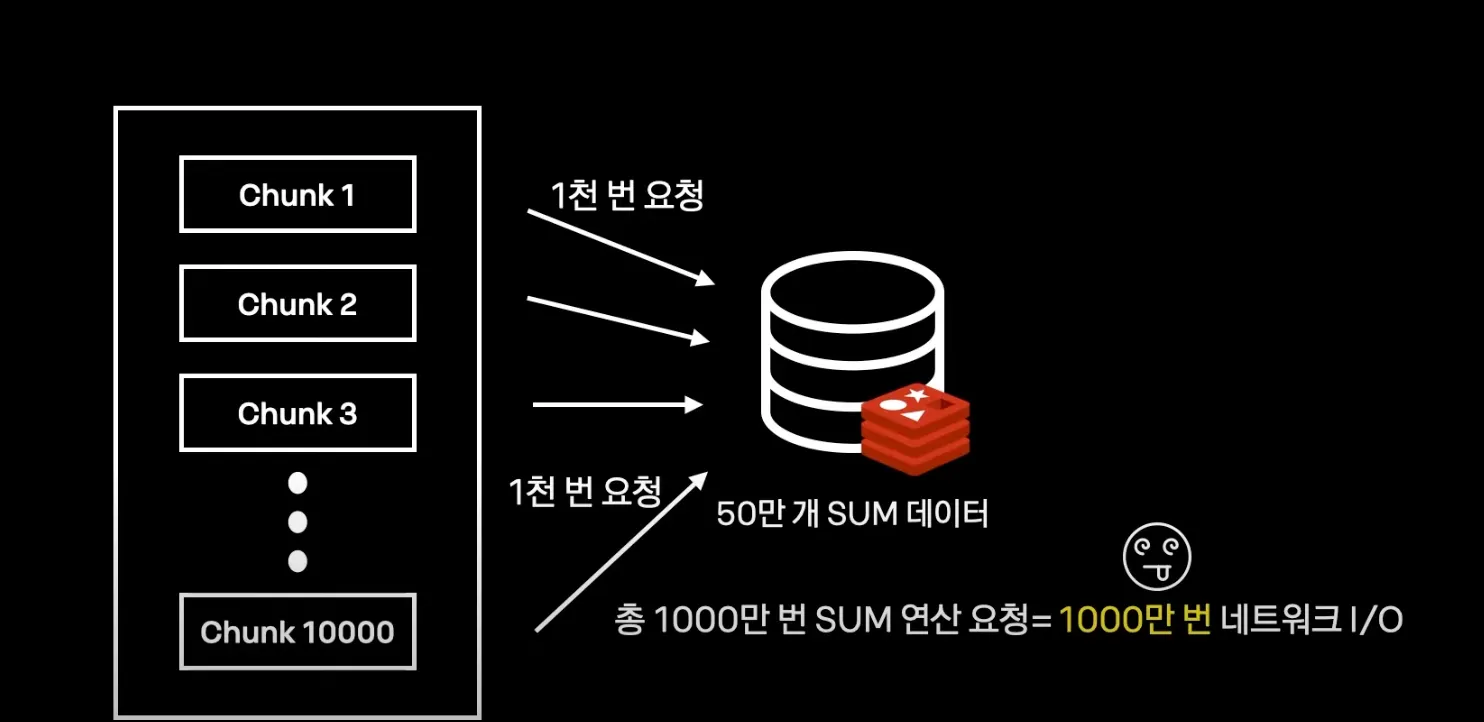
Redis를 도입해도 해결되지 않는 문제
•
네트워크킹에드는 레이턴시 1000만개의 데이터를 합산하기 위해서는 1000만 번 네트워크 I/O가 발생
Redis는 연산이 눈 깜짝할 사이에 끝나는데, Network I/O 요청 한 번당 1ms * 1000만 번 =3시간이 소요됨 때문에 성능이 오히려 저하됨.
Redis Pipeline으로 처리하자
redis pipeline : 다수 command를 한번에 묶어서 처리
Batch Application 전용
Redis Pipelin 대량 처리 라이브러리
별도 개발하여 사용 하고 있다.
(당연히 Spring Data Redis로 불가능ㅠ.ㅠ)
대량 데이터 WRITE
Reader와 Aggregation 까지 개션 완료
1000만 개 처리할 때는 여전히 느림 Writer를 개선해야됨.
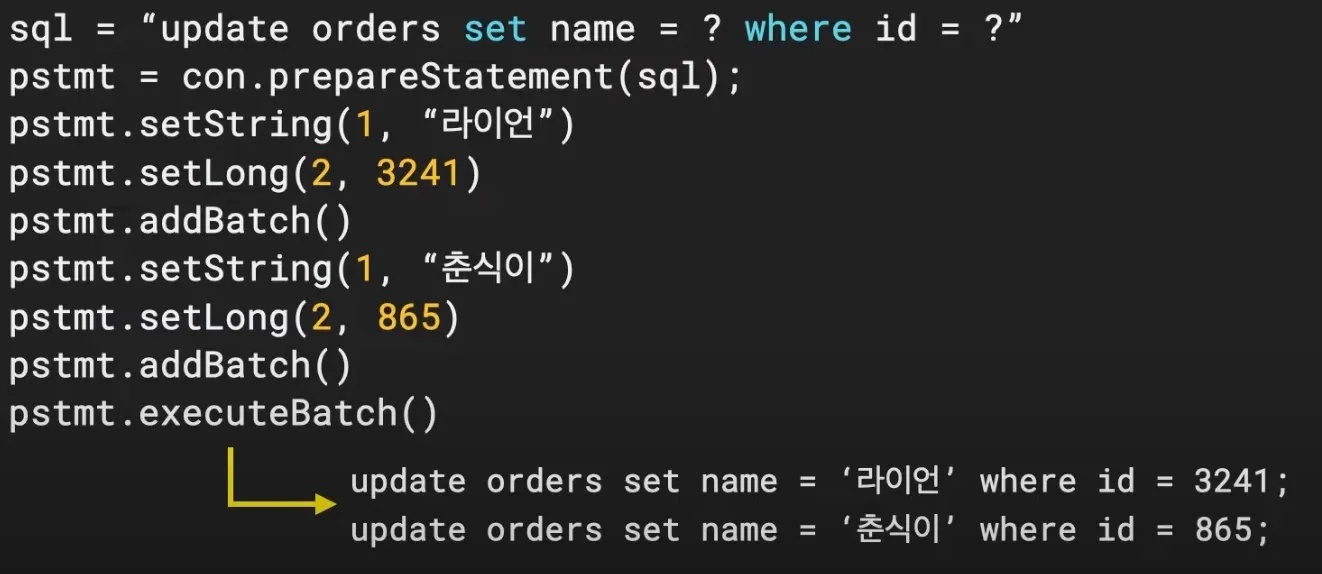
Batch Insert
•
일괄로 쿼리 요청
명시적 쿼리
•
필요한 컬럼만 Update
•
영속성 컨텍스트를 사용하지 않음(JPA는 사용하지 않는다.)
Batch에서 JPA WRITE에 대한 고찰
Batch 환경에서 JPA가 과연 잘 맞는가?
•
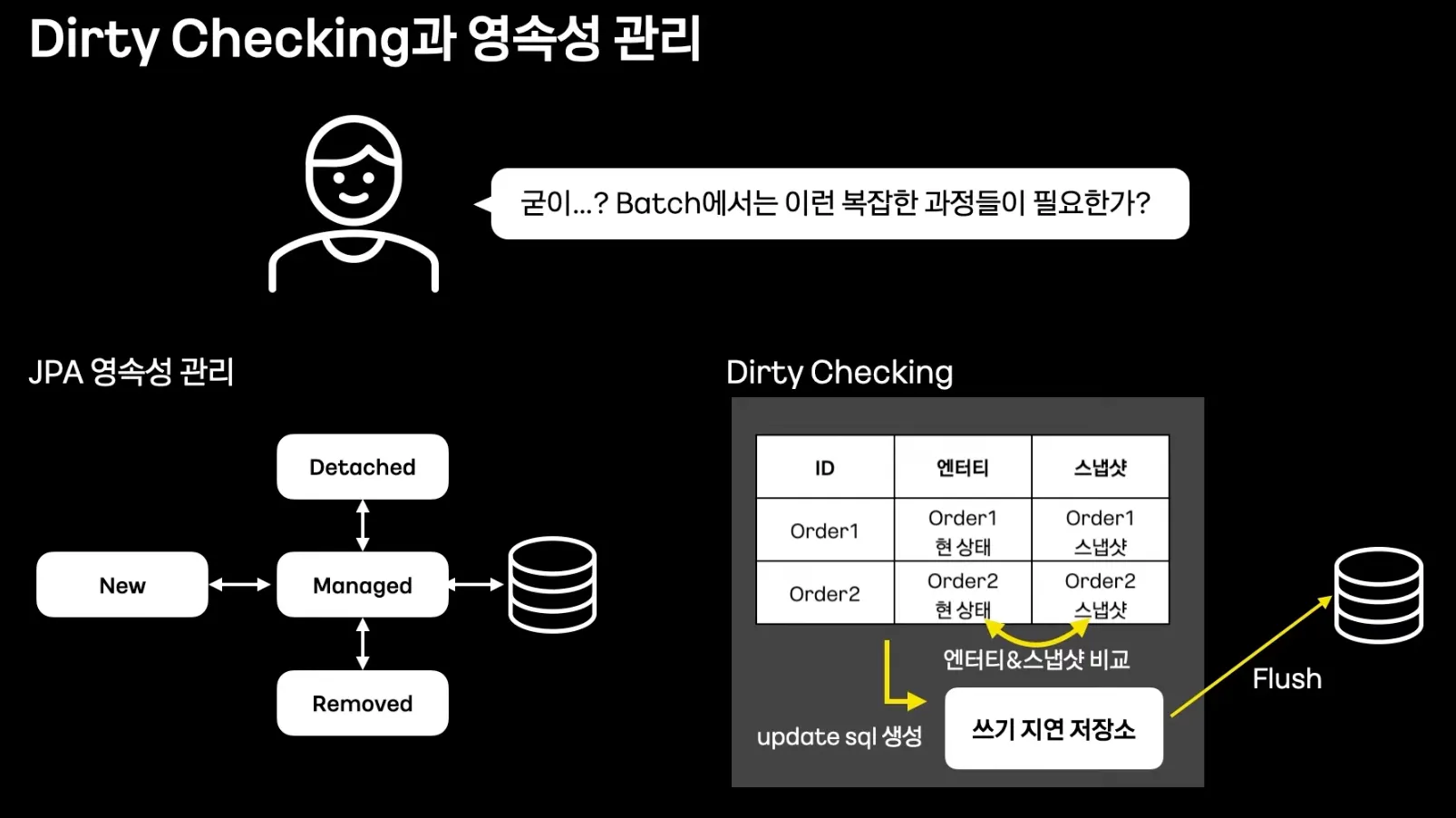
Dirty Checking과 영속성 관리
◦
Dirty Checking
•
UPDATE 할 때 불필요한 컬럼도 UPDATE
•
JPA Batch Insert 지원이 어려운 부분
Read 할 때부터 Dirty Checking과 영속성 버리기
요점은 Dirty Checking과 영속성 관리를 쓰지 않는것.
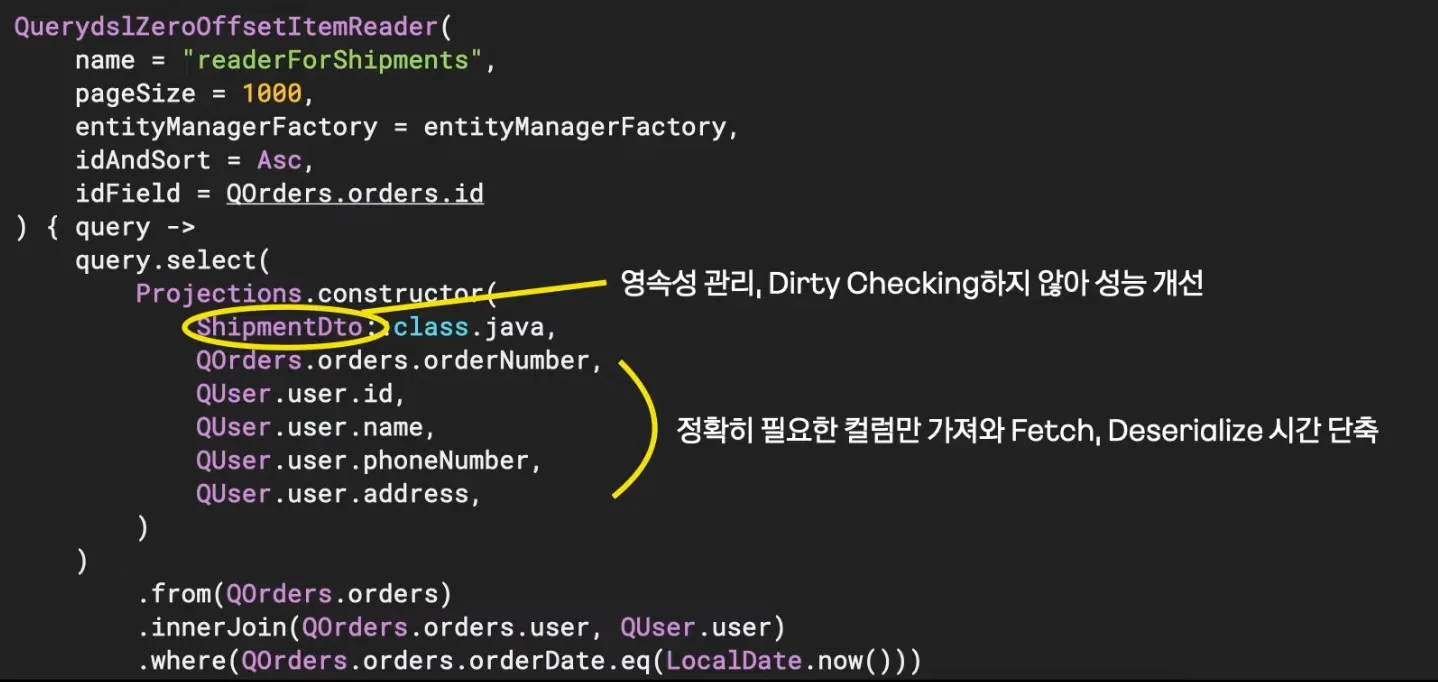
•
shipmentDto 는 엔티티가 아닌 DTO 이기 때문에 영속성 관리를 받지 않는다.
•
사용하는 컬럼만 가져와 Fetch, Deserialize 시간 단축
JPA가 UPDATE 할 때 불필요한 컬럼도 UPDATE를 진행함.

•
원하는 컬럼만 UPDATE 하는게 아니라 엔티티에 정의되어 있는 컬럼을 업데이트함
•
JPA Dynamic UPDATE도 있지만 동적 쿼리를 생성하는데 오히려 성능 저하를 일으킨다.
JPA Batch Insert 지원이 어렵다.
•
JPA에서도 Batch Insert를 지원하지만, ID 생성 전략을 IDENTITY로 하게되면 JPA 사상과 맞지 않는 다는 이유로 Batch Insert를 지원하지 않음.
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
Long id;
Java
복사
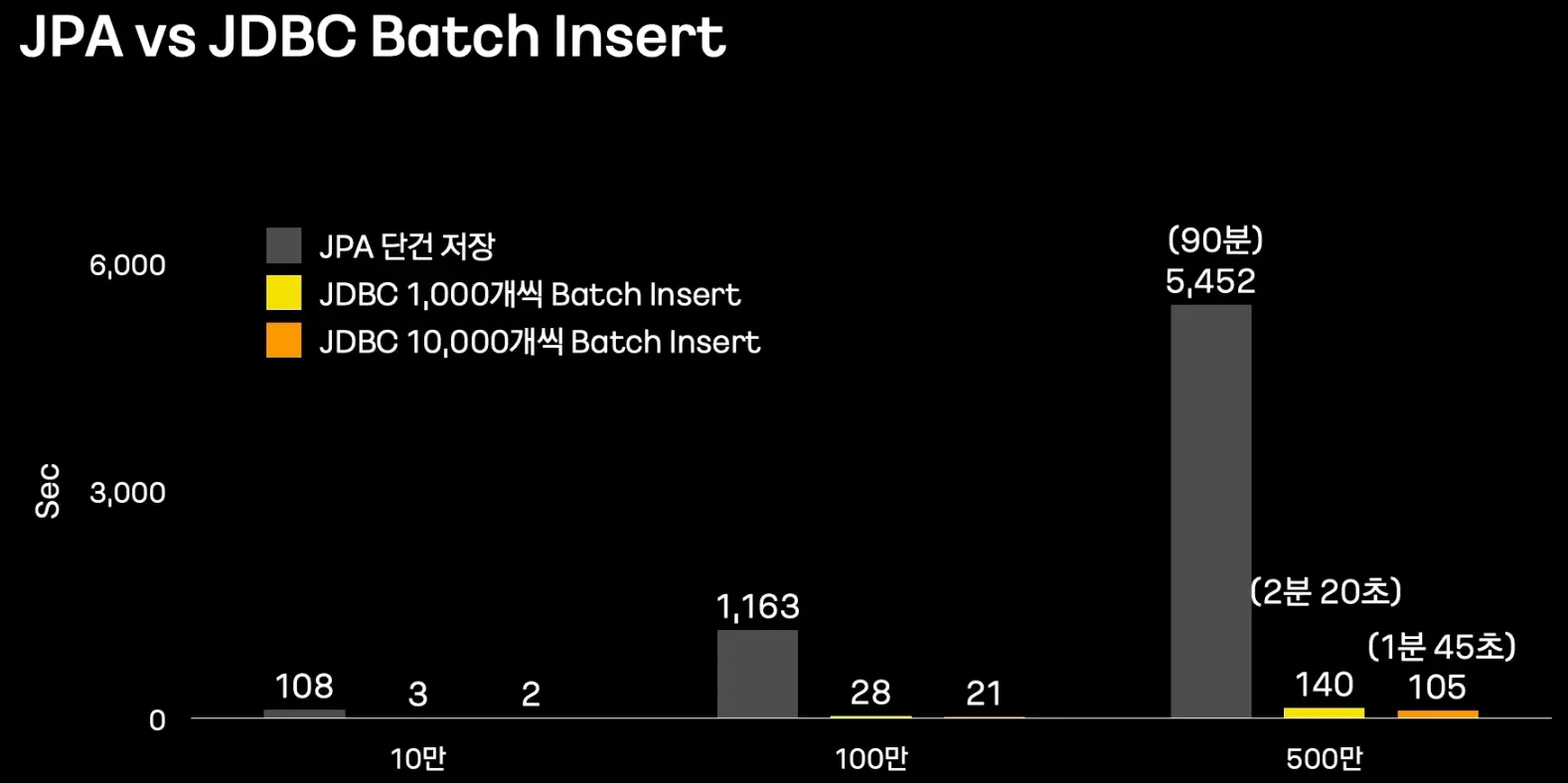
Batch에서 Batch Insert를 사용해야 하는 이유
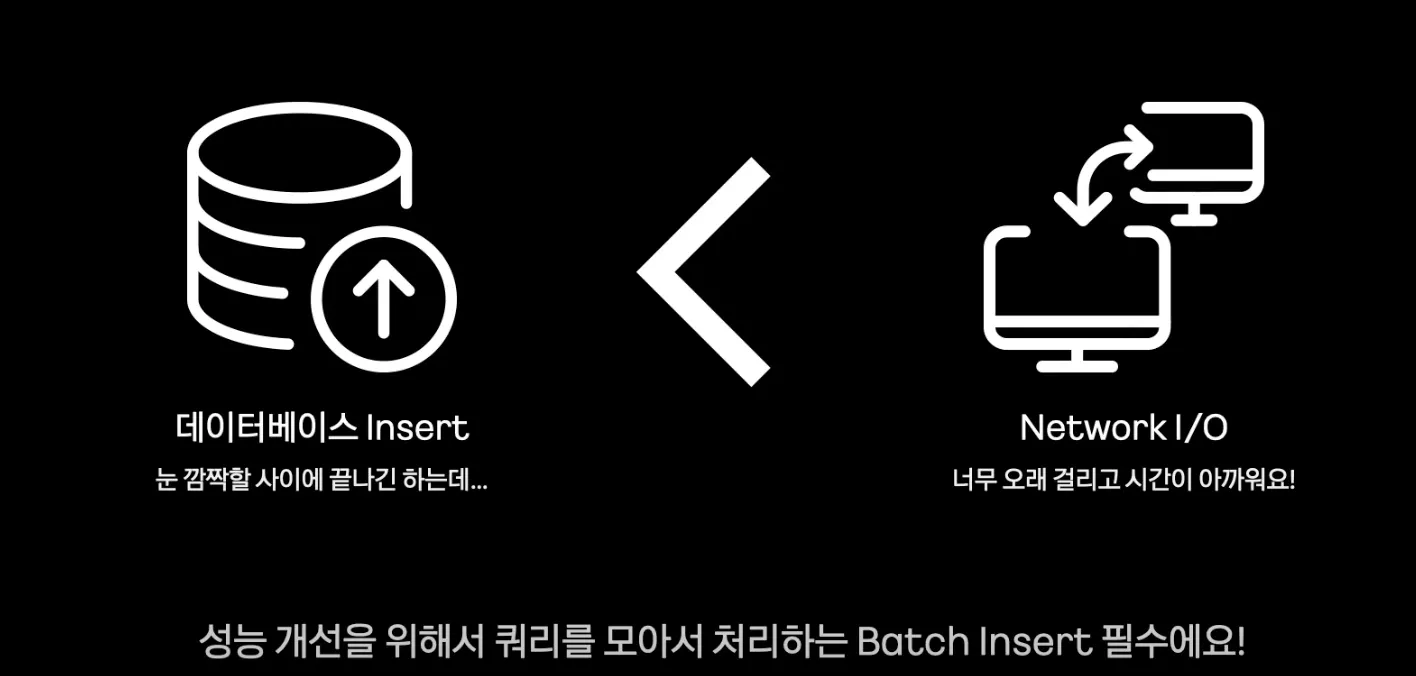
•
데이터베이스 Insert는 눈 깜짝 할사이에 끝나긴 하는데, 네트워크에 드는 레이턴시가 오래걸림. → 성능 개선을 위해서 쿼리를 모아서 처리하는 Batch Insert는 필수다.
Batch에서 JPA WRITE에 대한 고찰
•
Dirty Checking과 영속성 관리
→ 불필요한 check 로직으로 인한 큰 성능 저하
•
UPDATE 할 때 불필요한 컬럼도 UPDATE
→ 불필요한 컬러 UPDATE로 인한 소폭 성능 저하
•
JPA Batch Insert 지원이 어려운 부분
→ Batch Insert 불가한 경우, 매우 큰 성능 저하
결론
Writer에서 JPA를 포기하고 Batch Insert 할 것
사용 방법
효과적인 Batch 구동 환경
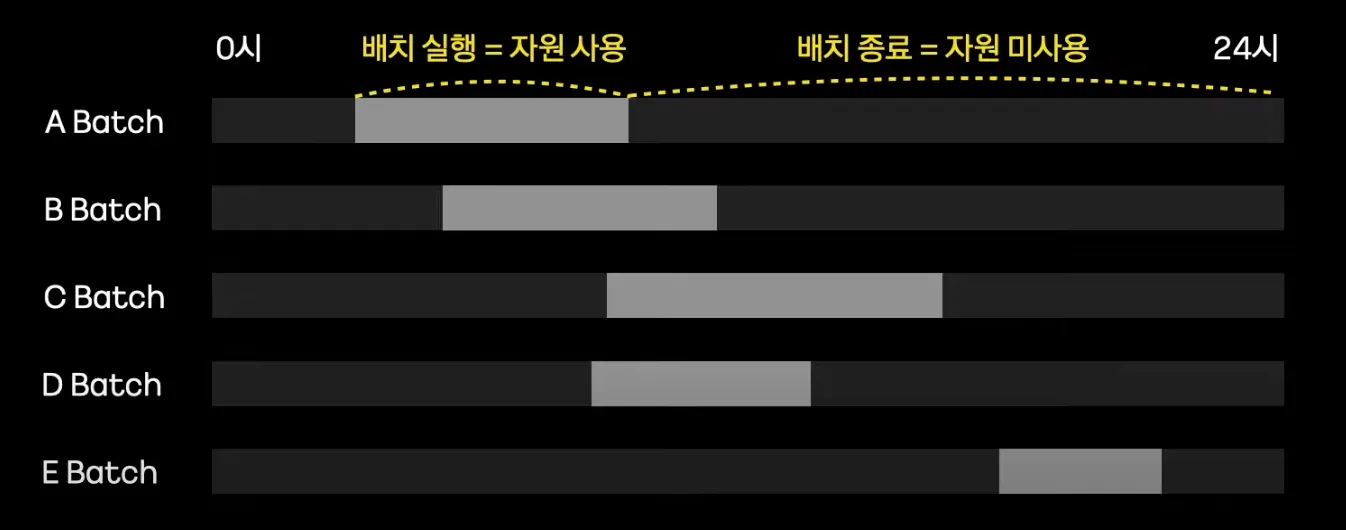
•
배치는 특정시간에만 자원을 할당하여 동작하고, 이후에는 자원을 사용하지 않는다. (os에 반납)
•
특정 시간대 배치와 데이터가 몰리면서 OOM을 발생시킬수 있다.
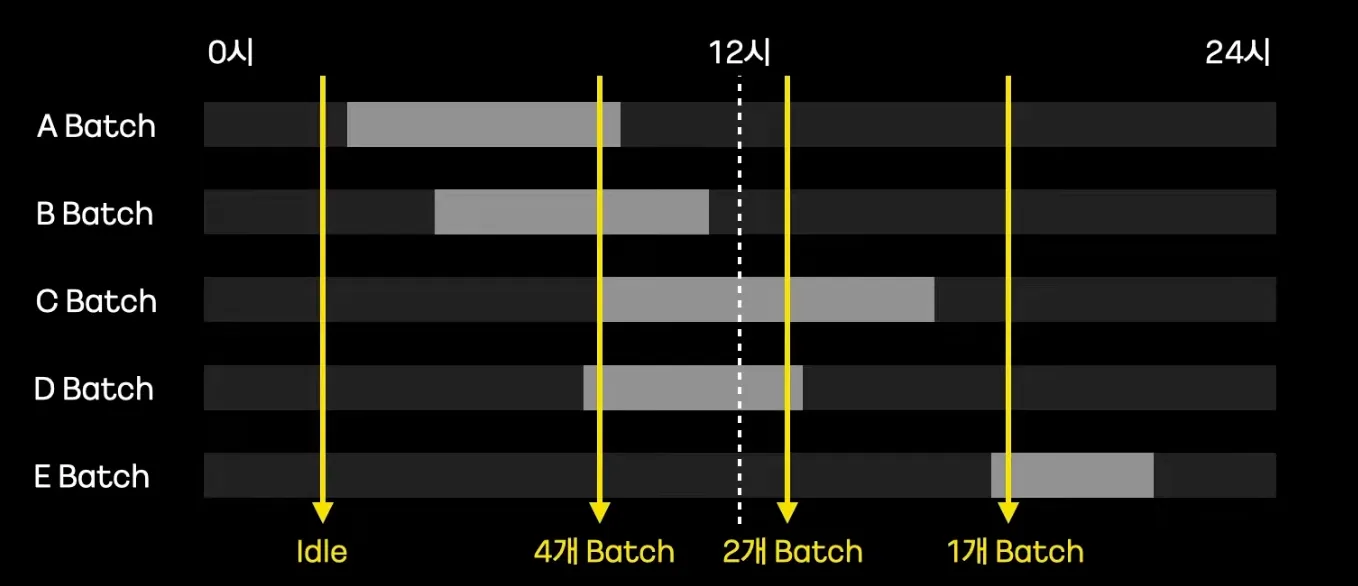
•
Batch에서는 동작 하나하나가 매우 길다.
•
대부분 스케줄 Tool에서 로그를 볼 수 있지만 로그 정보가 매우 빈약하다.
•
서비스 상태를 로그로 판단하는 것 자체가 전혀 시각적이지 않다.
Spring Cloud Data Flow 도입
데이터 수집, 분석, 데이터 입/출력과 같은 데이터 파이프라인을 만들고 오케스트레이션하는 툴
데이터 파이프라인 종류
•
Stream
•
Task(Batch)
장점
1.
오케스트레이션
a.
K8S와 완벽한 연동으로 Batch 실행 오케스트레이션 제공
→ 다수 Batch가 상호 간섭 없이 Running (by 컨테이너)
→ K8s에서 Resource 사용과 반납을 조율
2.
모니터링
a.
Spring Batch와 완벽한 호환 유용한 정보 시각적으로 모니터링
→ Spring Cloud Data Flow 자체 DashBoard 제공
→ 그라파냐 연동가능
Spring Cloud Data Flow 동작과 역할
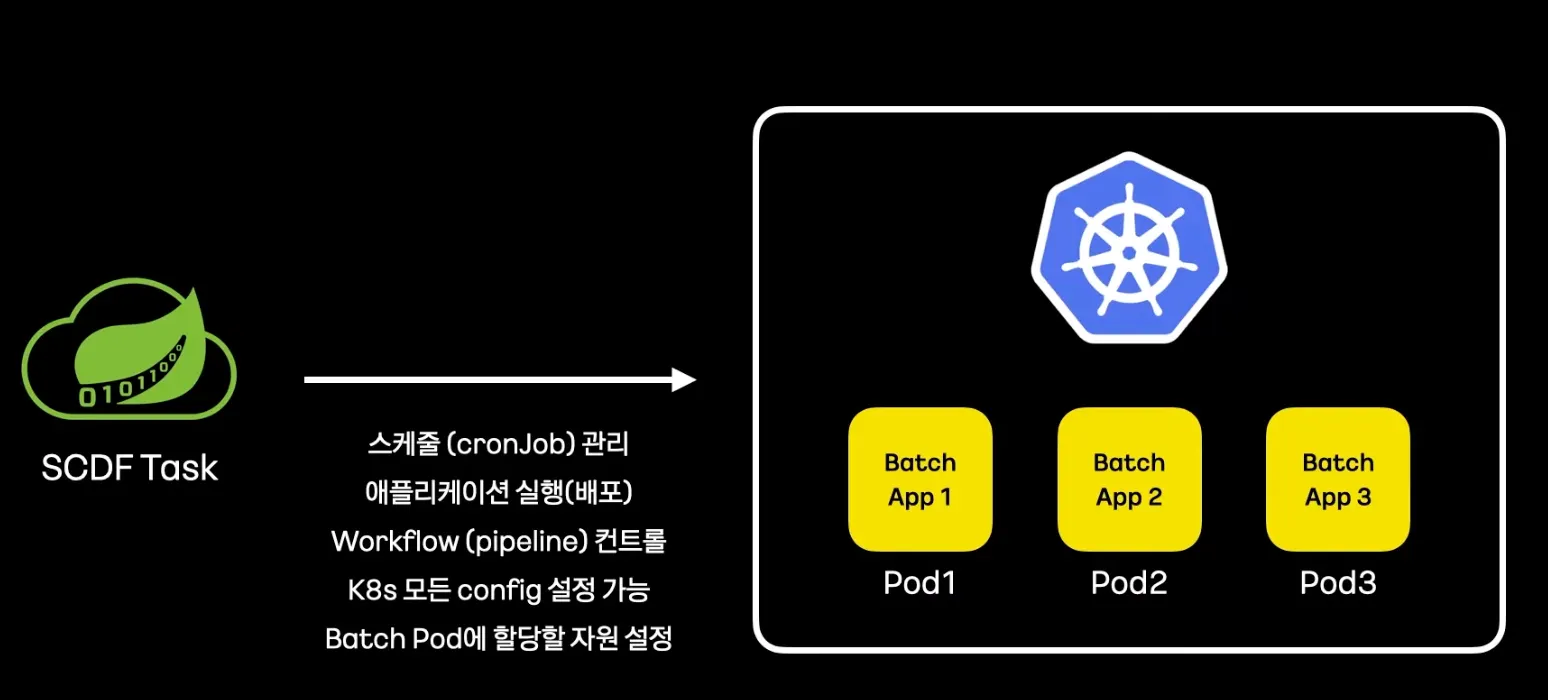
•
k8s의 크론잡을 사용해서 스케줄 관리
•
애플리케이션 실행 배포
•
배치의 실행 상태를 통제하는 Workflow를 컨트롤 할 수 있음
•
K8s의 모든 config를 설정할 수 있음 → 자원을 할당할 수 있음
•
Batch Pod에 할당할 자원 설정
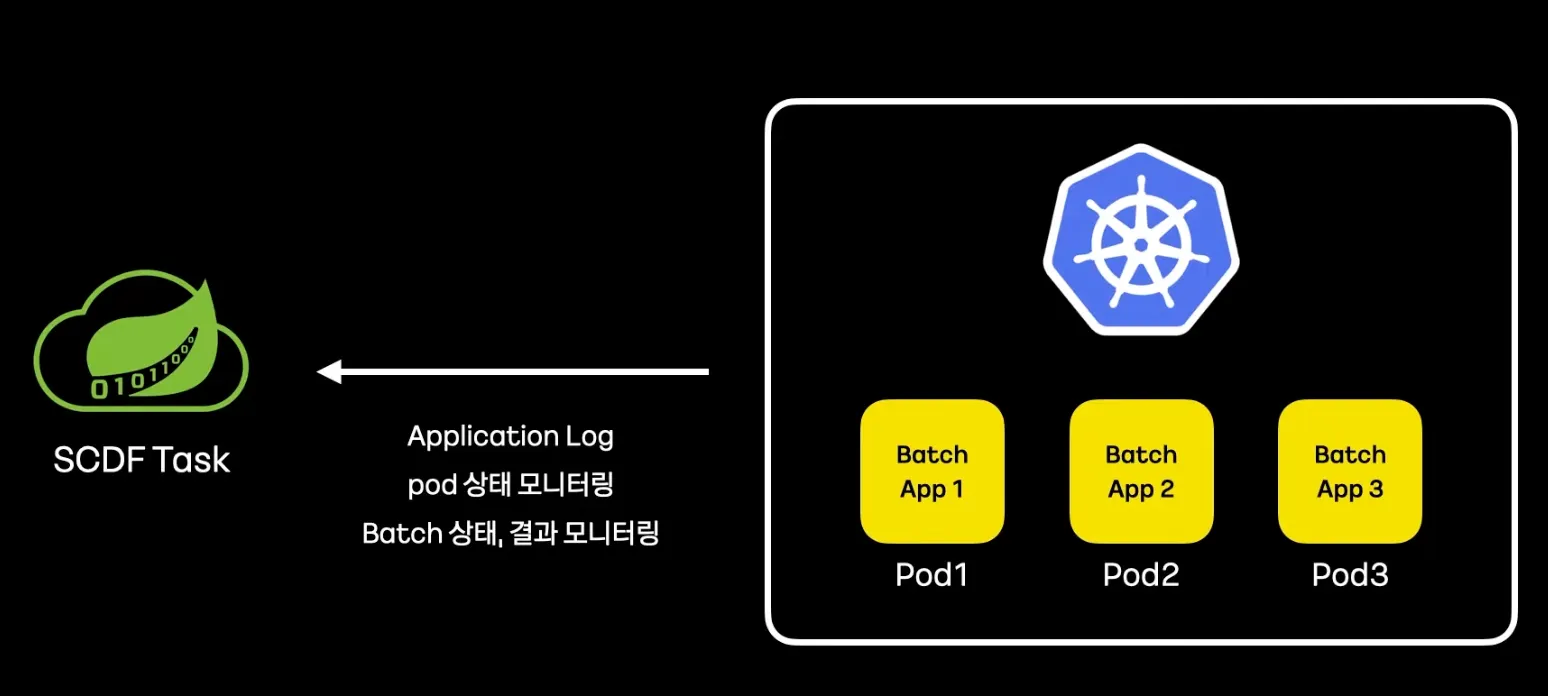
•
Application Log 제공
•
Pod 상태 모니터링
•
Batch 상태, 결과 모니터링
출처 :

