카프카 생태계
•
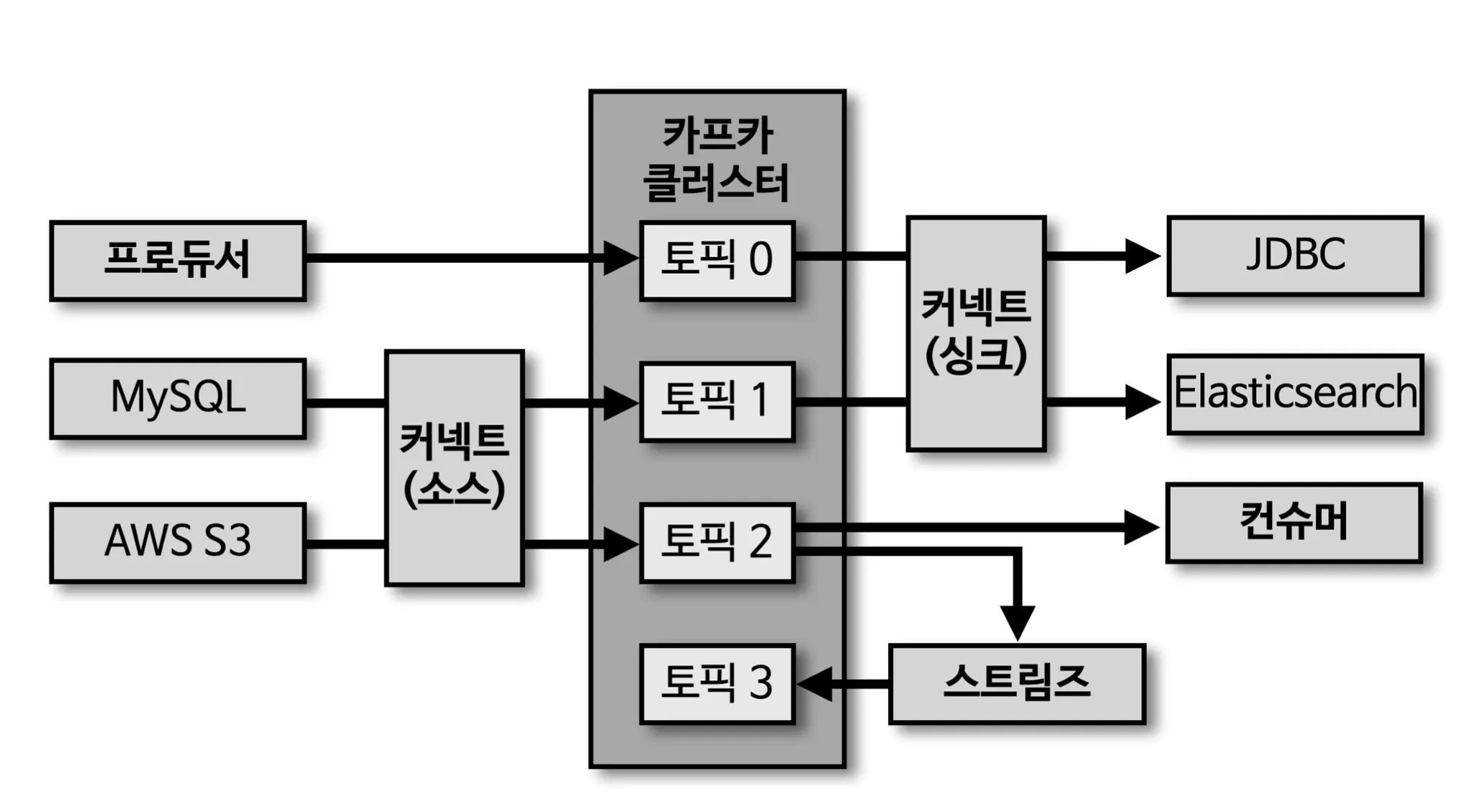
기본동작
◦
프로듀서 → 카프카클러스터 → 컨슈머
•
프로듀서에서 카프카 클러스트로 들어온 값을 신규 토픽으로 만들려면 스트림즈를 사용하면 된다.
◦
프로듀서 → 카프카 클러스터 → 스트림즈 → 토픽 순으로 변경하
•
커넥트 (소스) 와 커넥트 (싱크)는 소스는 프로듀서, 싱크는 컨슈머와 비슷한 역할을 한다.
◦
일반 프로듀서와 컨슈머와 다른 가장큰 차이점은 클러스터 단위로 운영한다는 것이고, 반복 적으로 템플릿 단위로 여러번 생성해서 사용할 수 있다.
카프카 브로커와 클러스터
•
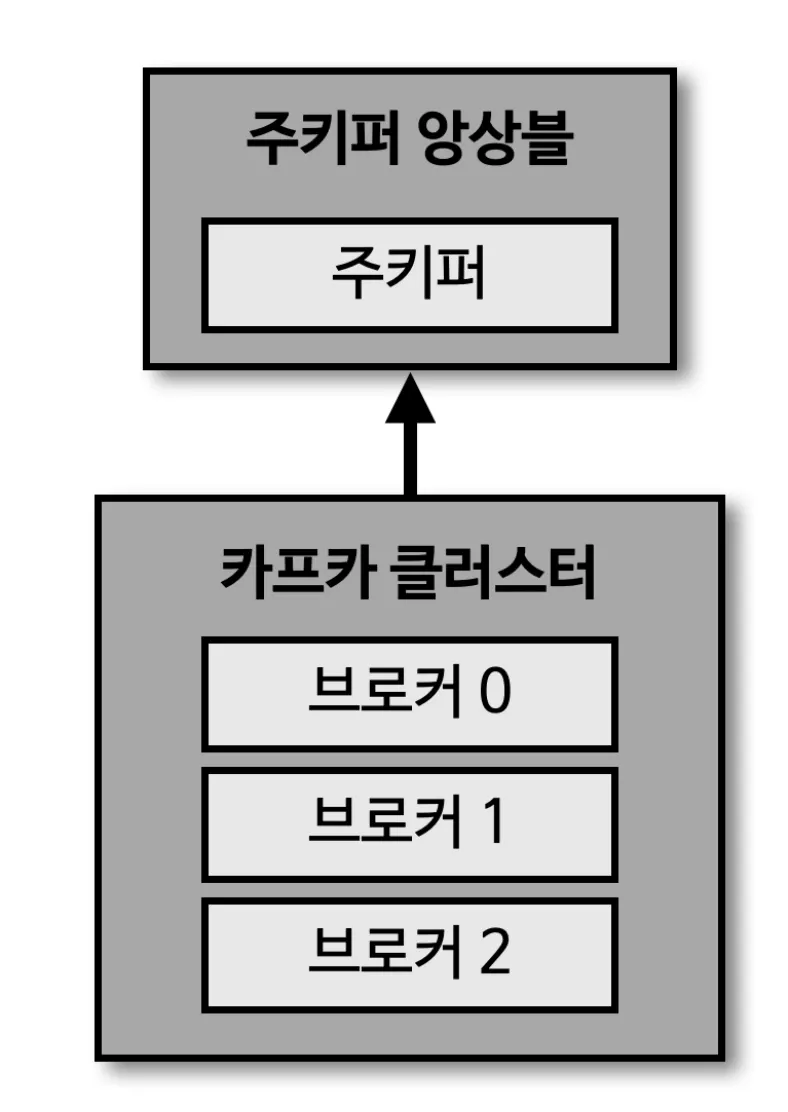
주키퍼 : 카프카 클러스트를 운영하기 위해 반드시 필요함
•
클러스터 : 여러대의 브로커를 의미한다.
•
브로커 : 하나의 서버에는 한개의 브로커 프로세스가 실행됨.
◦
한개로 운영이 가능하나 데이터를 안전하게 보관하고 처리하기 위해 기본적으로 3대 이상으로 운영한다.
◦
프로듀서가 데이터를 전송하게 되면, 3개의 브로커로 운영하게 될 시 브로커 0, 1, 2 모두 데이터를 저장하게 된다.
◦
1개의 클러스터에는 여러개의 브로커가 존재할 수 있다.
◦
일반적으로 3개로 운영하고, 데이터가 많다면 50 ~ 100개 까지 늘리는 경우가 있다.
여러개의 카프카 클러스터가 연결된 주키퍼
•
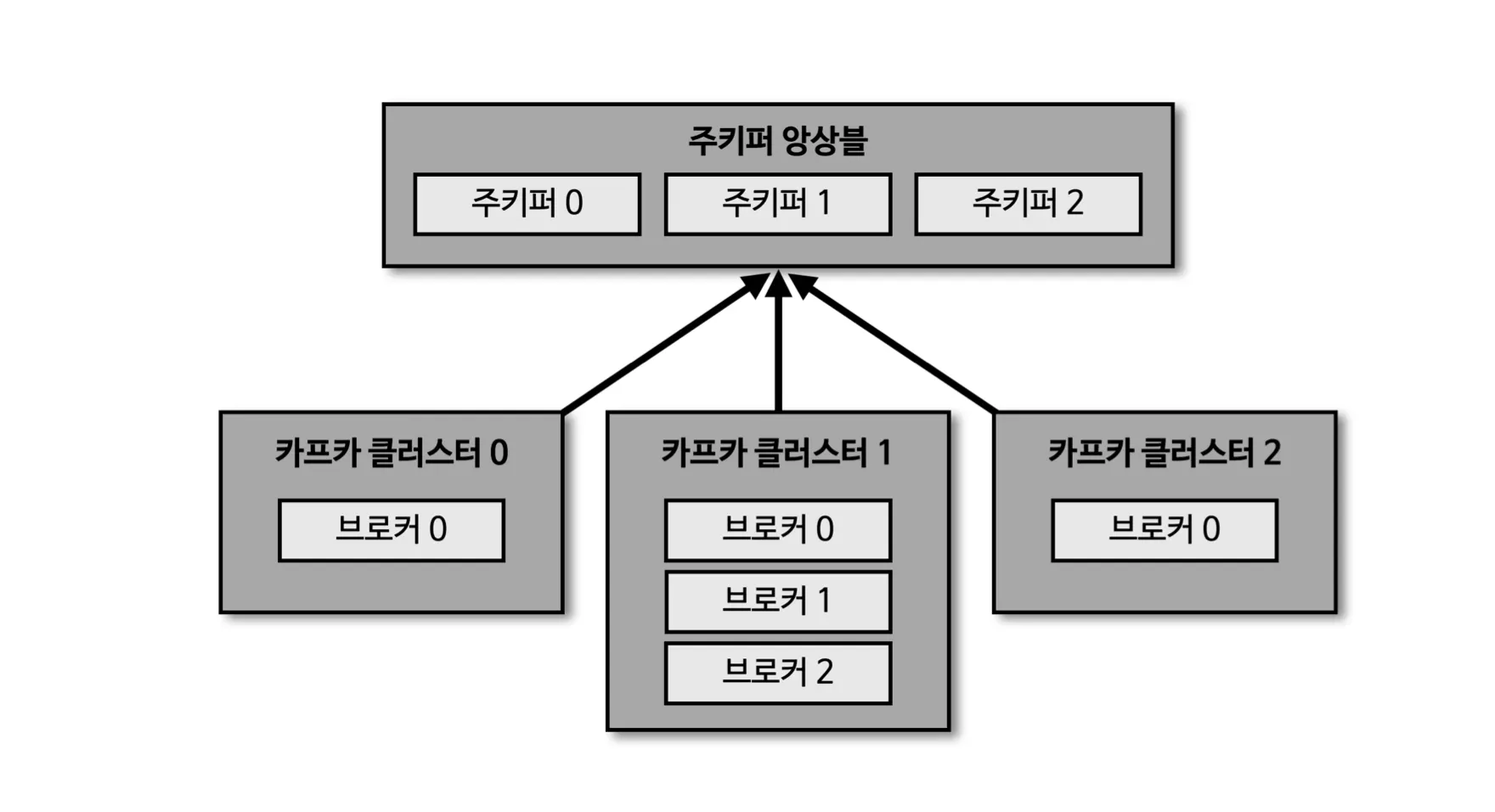
주키퍼 앙상블 : 하나의 주키퍼 앙상블에는 여러개의 주키퍼를 설정해놓고 여러개의 클러스터를 운영할 수 있다.
◦
ex) 카프카 클러스터 0 : 주문, 카프카 클러스터 1 : 배송, 카프카 클러스터 3 : 결제
◦
이렇게 하는 이유는? 클러스터를 운영하기 위해서는 하나의 주키퍼가 필수로 필요한데, 이렇게 될 경우 리소스 낭비가 발생되여 위와 같은 형태로도 운영한다.
브로커의 역할
•
컨트롤러
◦
클러스트 안에 다수중 한 대의 브로커가 컨트롤러 역할은 한다.
◦
컨트롤러는 다른 브로커들의 상태를 체크를 하며, 문제가 발생할 시 해당하는 브로커의 리더 파티션을 다른 브로커로 재분배 하게 해준다.
▪
지속적으로 실시간 데이터를 운여하기 위해.
◦
컨트롤러에 장애가 발생하면 → 다른 브로커가 컨트롤러 역할을 한다.
•
데이터 삭제
◦
카프카는 컨슈머가 데이터를 가져가도 삭제되지 않는다, 오직 브로커만 데이터를 삭제가 가능하다.
◦
데이터 삭제는 파일단위로 이루어지는데 이 단위를 로그세그먼트 라 부른다.
◦
데이터 삭제의 기준은
▪
용량 : 로그 세그먼트 단위로 지정 용량이 도래 되었을 때 삭제
▪
시간 : 로그 세그먼트 단위가 지정 시간이 도래 되었을 때 삭제
◦
특수한 상황일 때 : 최신 레코드 키를 제외하고 데이터를 삭제하고 싶을 때는 compact 옵션을 통해 삭제 할 수 있다.
•
컨슈머 오프셋 저장
◦
컨슈머 그룹은 파티션의 어느 레코드까지 가져갔는지 확인하기 위해서 오프셋을 커밋한다.
•
그룹 코디네이터
◦
컨슈머가 컨슈머 그룹에서 빠지면 매칭되지 않는 파티션을 정상 동작하게 컨슈머로 할당하여 끊임없이 데이터가 처리되게 도와준다.
브로커의 역할 - 데이터 저장
경로 : config/server.properties의 log.dir옵션에 저장한 디렉토리에 데이터를 저장
로그와 세그먼트

•
log.segment.byte : 바이트 단위의 최대 세그먼트 크기 지정. 기본 값은 1GB
•
log.roll.ms(hour) : 세그먼트가 신규 생성된 이후 다음 파일로 넘어가는 시간 주기. 기본 값은 7일
•
최초의 오프셋 번호가 파일의 이름이 된다. → 이는 로그파일이 몇번의 오프셋 까지 데이터가 저장됬는지 유추할 수 있게 해준다.
•
현재 쓰여지고 있는 세그먼트를 엑티브 세크먼트라고 한다.
세그먼트와 삭제 주기 (cleanup.policy = delete)

•
데이터 삭제 단위는 .log 파일 단위로 삭제가 가능하다, 레코드 별 오프셋은 삭제가 불가능하기 때문에 프로듀서, 컨슈머 각각에 대해 정말 유효한 데이터가 맞는지 확인하는 구문이 필요함.
•
retention.ms(minutes, hours) : 세그먼트를 보유할 최대 기간. 기본 값은 7일
◦
너무 많은 기간을 선택하게 될 시, 내 디스크 용량을 체크해서 진행해야된다.
◦
일반적으로 최대 기간을 3일로 지정한다. (토, 일)이 보통 휴무 이기 때문
•
retention.bytes : 파티션 로그 적재 바이트 값 기본 값은 -1
•
log.retention.check.interval.ms : 세그먼트가 삭제 영역에 들어 왔는지 확인하는 간격. 기본 값은 5분
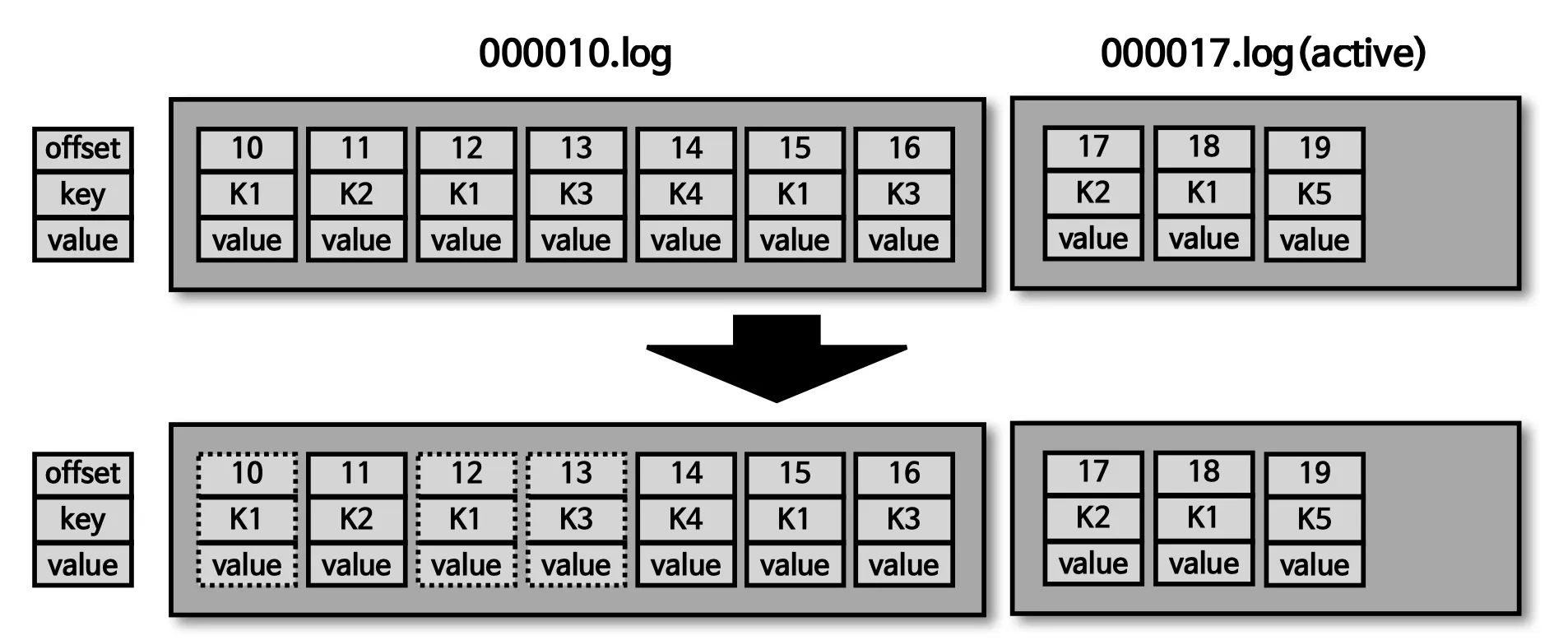
cleanup.policy=compact
•
key-value 형태로 중복된 값을 삭제하여, 최신의 데이터를 사용한다.
테일/헤드 영역, 클린/더티 로그
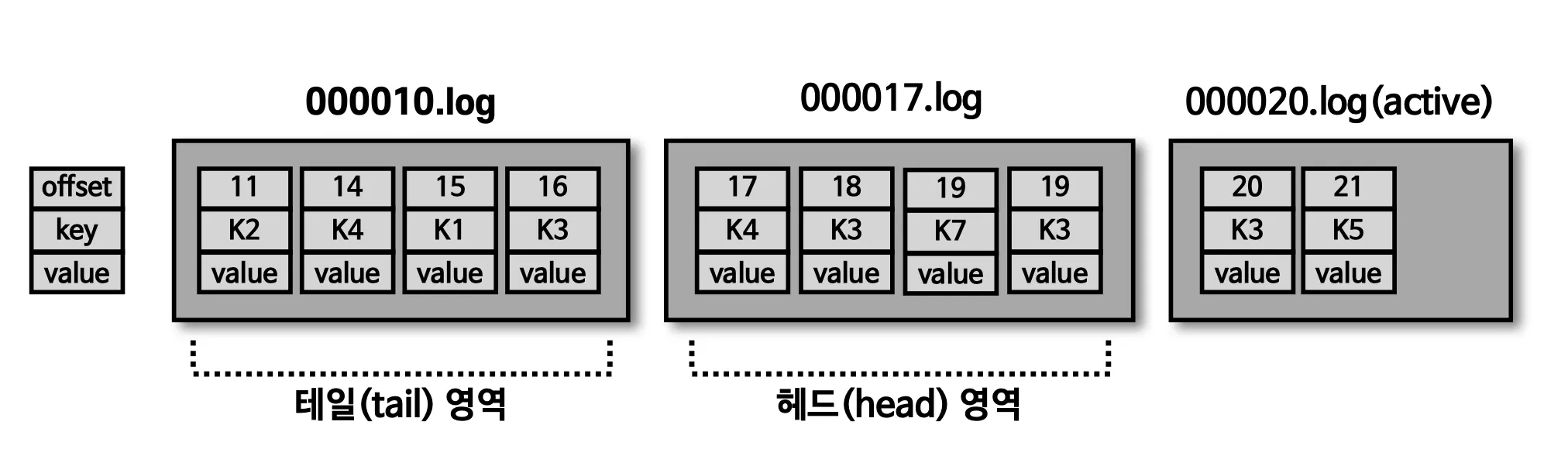
•
테일 영역 : 압축 정책에 의해 압출이 완료된 레코드들, 클린(clean)로그 라고 부른다. 중복 메시지 키가 없다.
•
헤드 영역 : 압축 정책이 되기 전 레코드들 더티(dirty)로그 라고도 부른다. 중복된 메시지 키가 있다.
min.cleanable.dirty.ratio
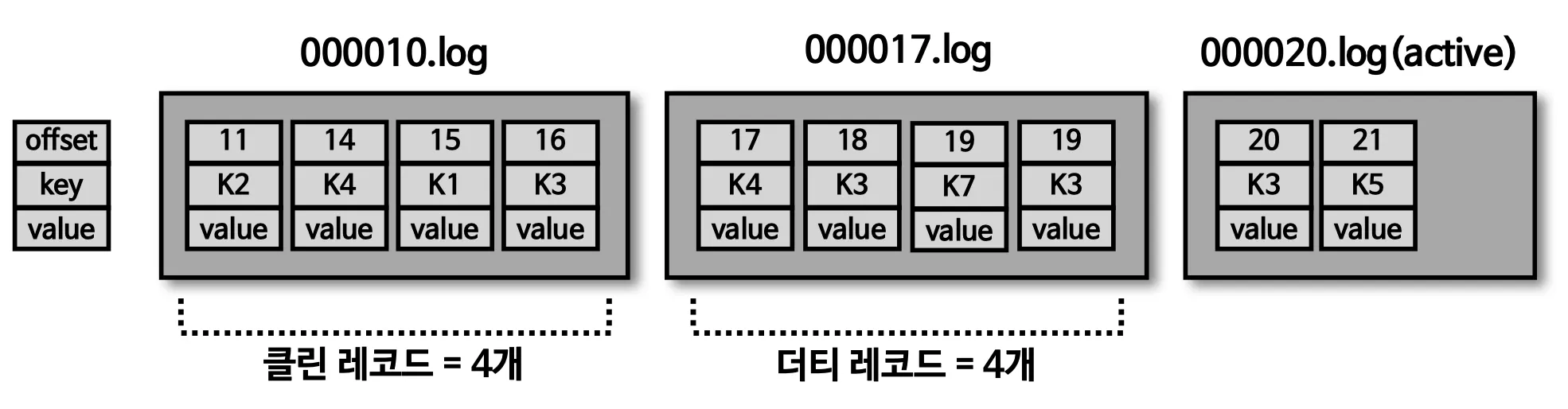
•
데이터의 압축 시작 시점은 min.cleanable.dirty.ratio 옵션값을 따름
◦
테일 영역의 레코드 개수와 헤드 영역의 레코드 개수의 비율을 뜻하며, 0.5로 설정한다면 테일 영역의 레코드 개수가 헤드 영역의 레코드 개수와 동일할 경우 압축이 진행된다.
브로커의 역할 - 복제 (Replication)
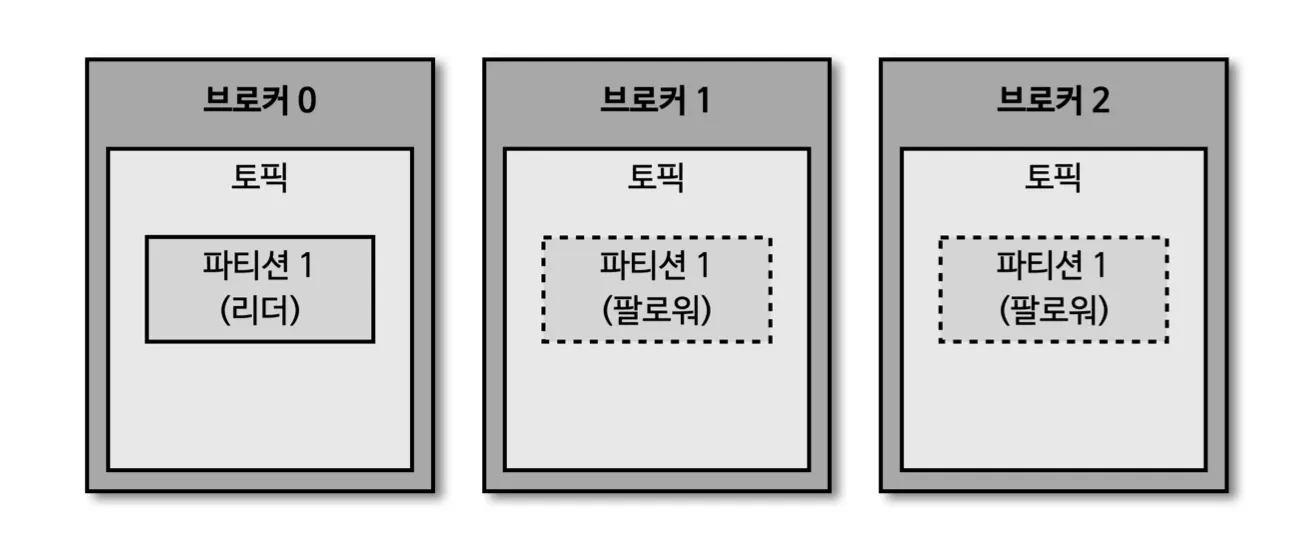
•
데이터 복제는 카프카를 장애 허용시스템으로 동작하도록 하는 원동력이다.
•
데이터 복제는 파티션 단위로 이루어진다.
•
토픽을 설정할 때 파티션 갯수도 설정한다. 이때 파티션 갯수 옵션을 설정하지 않으면 브로커 설정 기반으로 설정이 된다.
•
복제의 갯수는 최소값 1(복제 없음) 이고, 최대값은 브로커 갯수만큼 설정하여 사용할 수 있다.
•
팔로워 파티션은 리더의 파티션의 오프셋을 확인하여 자신이 가지고 있는 오프셋과 비교하고, 없는 데이터를 복제하여 가져온다.
•
보통 복제는 2~3으로 설정하여 동작시킨다.
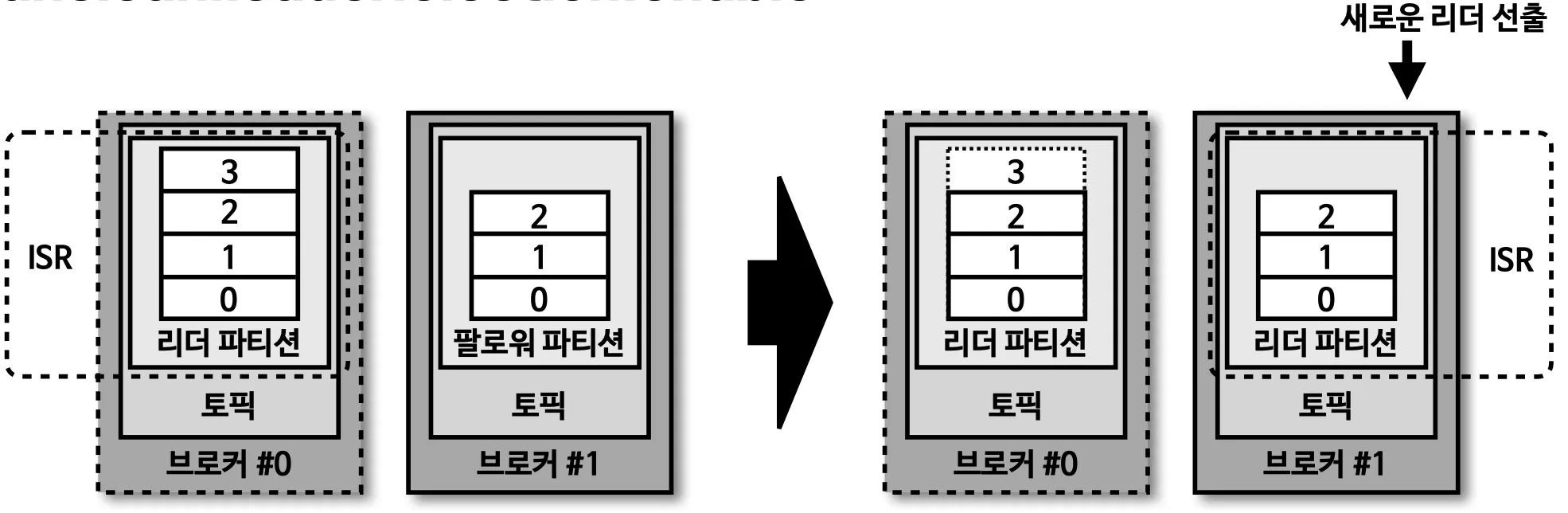
ISR(In-Sync-Replicas)
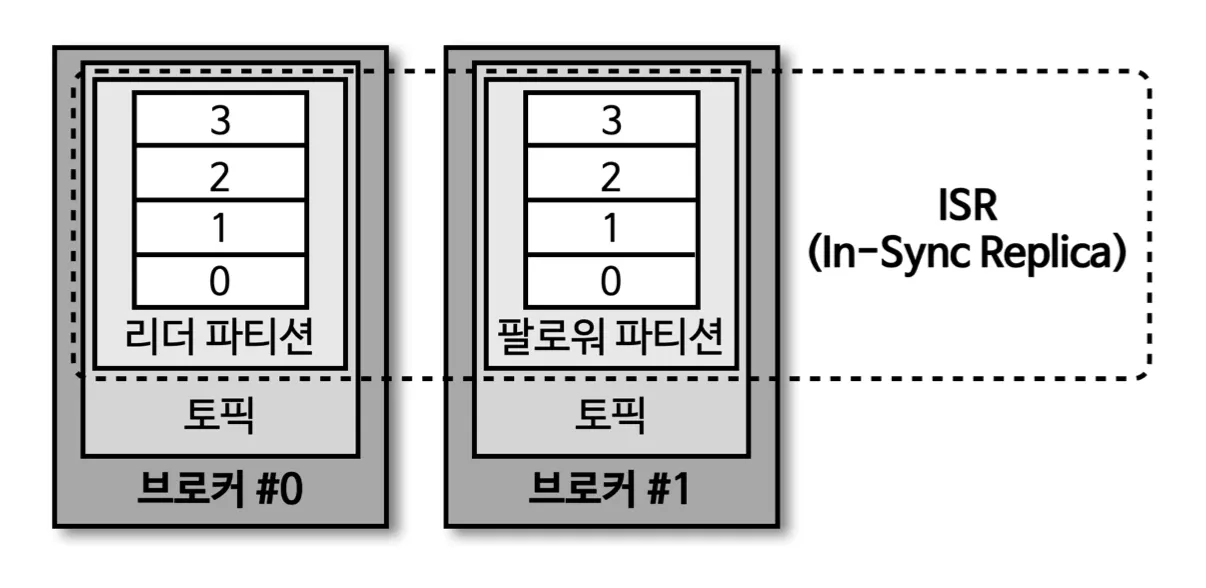
•
리더 파티션과 팔로워 파티션이 모두 싱크가 된 상태
•
팔로워 파티션이 리더 파티션의 복제를 다 하지 못한 상태에서 리더 파티션이 장애가 발생하게 되면, 데이터가 유실 될 수 있다. 이때 유실된 데이터를 무시하고 계속 데이터를 진행하려면 옵션을 줘야 된다.
•
unclean.leader.election.enable = true : 유실을 감수, 복제가 안된 파티션 팔로워를 리더로 승급
•
unclean.leader.election.enable = false : 유실을 감수 하지 않음 , 해당 브로커가 복구될 때 까지 중단.
토픽과 파티션
•
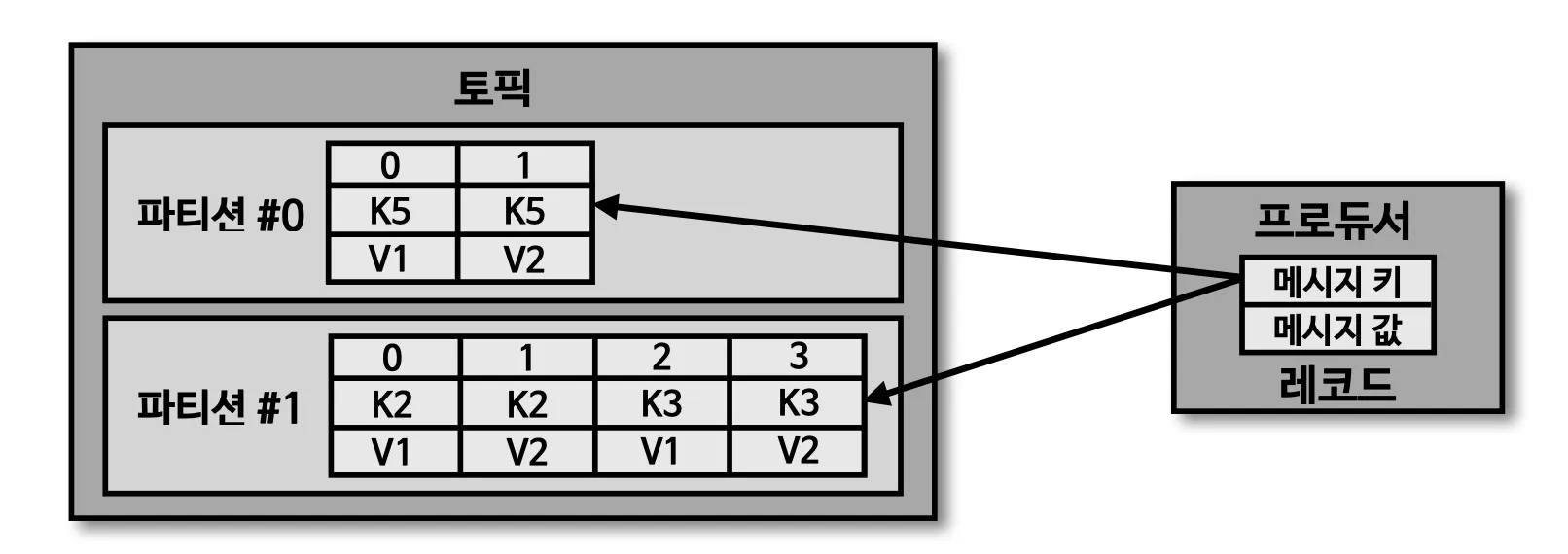
토픽 : 카프카에서 데이터를 구분하기 위해 사용하는 단위
•
파티션 : 프로듀서가 보내 데이터들이 들어가 저장되는 곳 이 데이터를 레코드라 부른다.
파티션의 레코드는 컨슈머가 가져가는 거소가 별개로 관리, 이러한 특징 때문에 레코드는 다양한 목적을 가진 여러 컨슈머 그룹들이 토픽의 데이터를 여러번 가져갈 수 있다.
토픽 생성시 파티션이 배치되는 방법

•
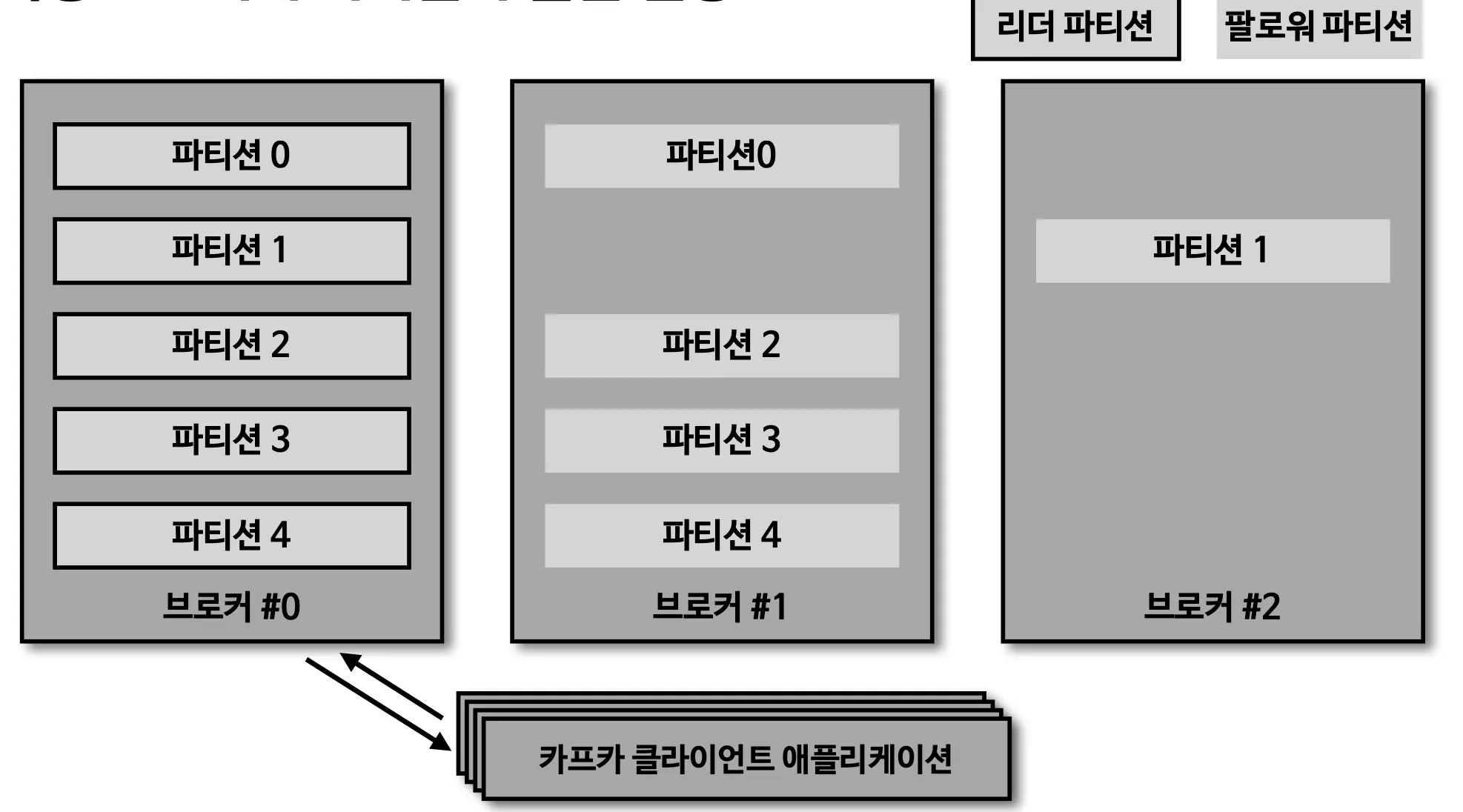
파티션이 5개라고 가정하면 그림과 같으 0번 브로커 부터 시작하여 round-robin 방식으로 리더 파티션들이 생성 됨.
•
카프카 클라이언트는 리더 파티션이 있는 브로커와 통신하여 데이터를 주고 받으므로 여러 브로커에 골고루 네트워크 통신을 하게 된다. → 데이터가 특정 브로커에 집중되는 hot spot 현상을 방지
토픽 생성시 파티션이 배치되는 방법

•
위와 같이 리더 파티션이 만들어 지면 순차적으로 팔로워 파티션이 만들어짐.
특정 브로커에 파티션이 쏠린 현상
•
파티션 개수와 컨슈머 개수의 처리량  ️️️
️️️

•
파티션은 카프카의 병렬처리의 핵심으로써 그룹으로 묶인 컨슈머들이 레코드를 병렬로 처리 할 수 있도록 매칭된다.
•
컨슈머의 처리량이 한정된 상황에서 많은 레코드를 병렬로 처리하는 가장 좋은 방법은 컨슈머의 개수를 늘려 스케일 아웃하는 것
•
컨슈머 개수를 늘림과 동시에 파티션 개수도 늘리면 처리량이 증가하는 효과를 볼 수 있다.
•
현재 프로듀서가 데이터를 1초당 10개의 데이터를 보내고, 컨슈머는 초당 1개의 데이터를 처리한다고 가정하면, 컨슈머 렉이 발생이 되면서 지연이 발생한다.
•
이를 방지하기위해 파티션의 개수를 늘리고 컨슈머의 개수를 늘려 병목현상이 발생되는 부분을 풀어줘야된다.
중요한 것은 파티션 갯수를 늘리면 줄이수 없다는 것이다. 때문에 파티션을 늘릴때에는 신중할 필요가 있다.
레코드
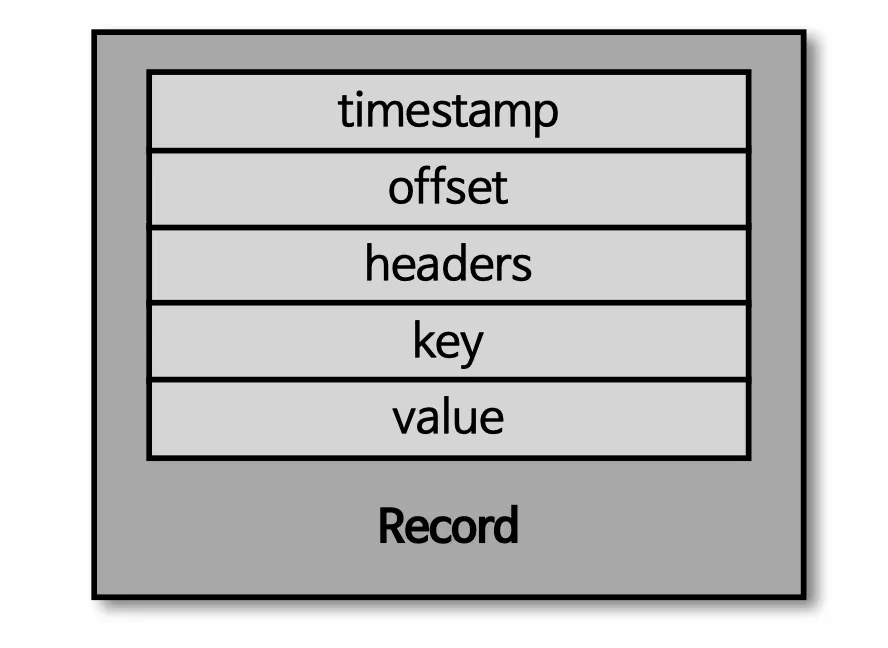
레코드 구성
•
타임스템프
•
헤더
•
메세지 키
•
메세지 값
•
오프셋
프로듀서가 생성한 레코드가 → 브로커로 전송되면 오프셋과 타임스템프가 저장된다. 브로커에 한번 적재된 레코드는 수정할 수 없다. 로그 리텐션 기간 또는 용량에 의해 삭제된다.
토픽 작명의 템플릿과 예시
<환경>.<팀-명>.<애플리케이션-명>.<메시지-타입>
예시) prd.marketing-team.sms-platform.json
<프로젝트-명>.<서비스-명>.<환경>.<이벤트-명>
예시) commerce.payment.prd.notification
<환경>.<서비스-명>.<JIRA-번호>.<메시지-타입>
예시) dev.email-sender.jira-1234.email-vo-custom
<카프카-클러스터-명>.<환경>.<서비스-명>.<메시지-타입>
예시) aws-kafka.live.marketing-platform.json

